阿里云Qwen3‑TTS开源发布 多语言实时语音合成实现细粒度声线控制
•39 阅读•4分钟•开源
多语言开源TTS阿里Qwen
•39 阅读•4分钟•开源
背景介绍
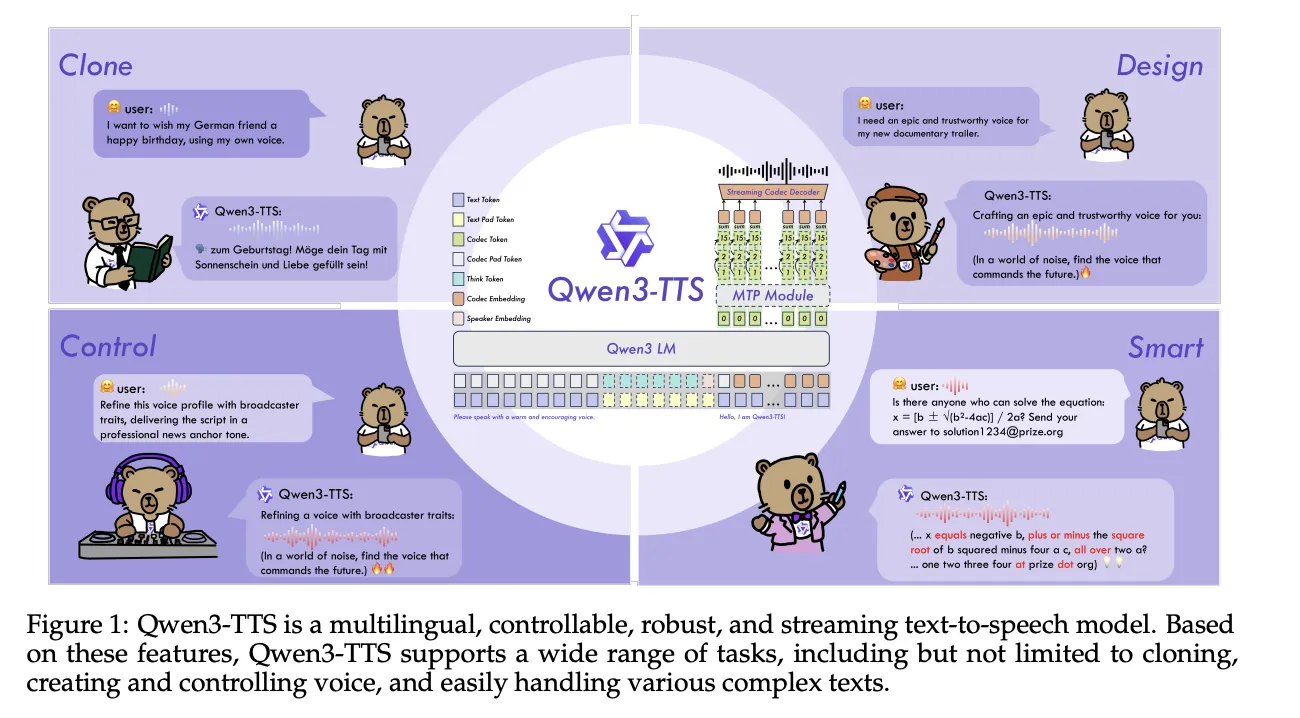
阿里云旗下的Qwen实验室在近期的ArXiv论文中公布了完整的多语言文本转语音(TTS)套件——Qwen3‑TTS。该项目以Apache 2.0许可证开源,旨在为科研和工业界提供“一栈三任务”的统一解决方案:高保真语音生成、极速克隆以及基于自然语言描述的声线创作。
模型架构与技术亮点
- 双轨语言模型:一条轨道负责从文本预测离散声学码元,另一条轨道处理对齐与可控信号,实现了高效的流式解码。
- 12Hz Tokenizer:采用12.5 fps(约80 ms/Token)的离散编码器,使用16个量化器和2048条码本,支持每个流式包 320 ms 音频的即时播放。
- 模型规模:提供 0.6 B 与 1.7 B 两种参数规模,分别对应基础模型(Base)和定制声线模型(CustomVoice、VoiceDesign)。
- 任务划分:
Base:通用 TTS 与零-shot 声线克隆;CustomVoice:9 种预设声线(如 Vivian、Ryan、Ono_Anna),可通过简短描述直接调用;VoiceDesign:接受自然语言指令生成全新声线,支持“紧张的青少年男性”之类的细粒度控制。
性能评测
在 LibriSpeech clean 测试集上,Qwen3‑TTS‑12Hz‑1.7B‑Base 达到 PESQ 3.21、STOI 0.96、UTMOS 4.16,领先同类语义 Tokenizer。流式解码首包延迟约 97 ms(0.6 B) 与 101 ms(1.7 B),并在并发 6 条时保持低于 340 ms 的响应。
多语言评测覆盖 10 种语言,模型在中文、英文、意大利语、法语、韩语、俄语六语种实现最低 WER,且在全部语言上获得最高的说话人相似度。零-shot 英文克隆的 Word Error Rate 为 1.24,刷新公开数据集记录。跨语言克隆(如中文→韩语)误差率下降约 66%,显示出强大的跨语言迁移能力。
开源生态与使用指南
- 代码与模型权重:全部托管于 GitHub,提供 PyTorch 与 TensorRT 推理示例;
- Tokenizer 包:
Qwen3‑TTS‑Tokenizer‑12Hz可单独下载,用于离线编码/解码; - 快速入门:官方 README 包含 Docker 镜像、一键部署的 Flask/Gradio 演示以及 RESTful API 文档;
- 社区支持:已在 Reddit、Telegram 等平台建立 10 万+ 开发者社群,提供技术答疑与模型微调经验分享。
行业意义
Qwen3‑TTS 的发布标志着国产开源语音技术进入了“实时+多任务”新阶段。低延迟流式解码满足了互动式语音助手、在线教育以及游戏配音等对时效性要求极高的场景;而指令式声线创作则为内容创作者提供了前所未有的个性化工具。结合阿里云强大的算力资源,Qwen3‑TTS 有望在国内外市场形成生态闭环,推动生成式语音从实验室走向商业化落地。
“我们希望通过开放完整的技术栈,让每一位开发者都能在自己的产品中自由使用高质量的多语言语音合成。”——Qwen团队负责人
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。