LightSeek推出TokenSpeed开源推理引擎,实现TensorRT-LLM级别性能,专为Agent工作负载设计
•81 阅读•4分钟•开源
NVIDIAKimiAgenticLightSeekTokenSpeed
•81 阅读•4分钟•开源
背景
随着 Claude Code、Codex、Cursor 等代码生成 Agent 从单机工具演进为支撑大规模软件开发的基础设施,推理服务的吞吐与响应成为制约规模化落地的关键瓶颈。传统聊天式 LLM 推理往往以单轮、短上下文为主,而 Agent 工作负载的上下文常常突破 5 万 token,且对每用户每秒请求数(TPS)有严格要求。为了解决这一痛点,LightSeek 基金会在 MIT 许可下推出了 TokenSpeed,定位为面向 Agent 场景的高效推理引擎。
TokenSpeed 架构亮点
- 编译器驱动的并行建模:采用本地 SPMD(Single Program Multiple Data)模型,开发者只需在模块边界标注 I/O 位置,轻量编译器自动生成通信算子,省去手工实现分布式通信的成本。
- C++ 有限状态机调度器:调度层与执行层分离,调度器以有限状态机形式在编译期验证 KV 缓存安全,实现对 KV 迁移与使用的类型系统约束,显著降低运行时错误。
- Python 执行平面:核心执行逻辑保留在 Python 中,兼顾快速特性迭代与开发者友好度。
- 可插拔内核层:GPU 内核被抽象为第一类模块,提供统一 API、注册中心与插件机制,支持异构加速器,未锁定 NVIDIA 硬件。
- 高效 MLA 核心:针对 Agent 工作负载的多头注意力(MLA)内核在 NVIDIA Blackwell 上实现了 q_seqlen 与 num_heads 的融合调度,充分利用 Tensor Core;二进制预填充内核亦通过软最大实现细调,已被 vLLM 采纳。
- SMG 入口:基于 PyTorch 的 SMG 组件提供低开销的 CPU‑GPU 请求入口,缩短调度层与 GPU 执行层之间的切换时延。
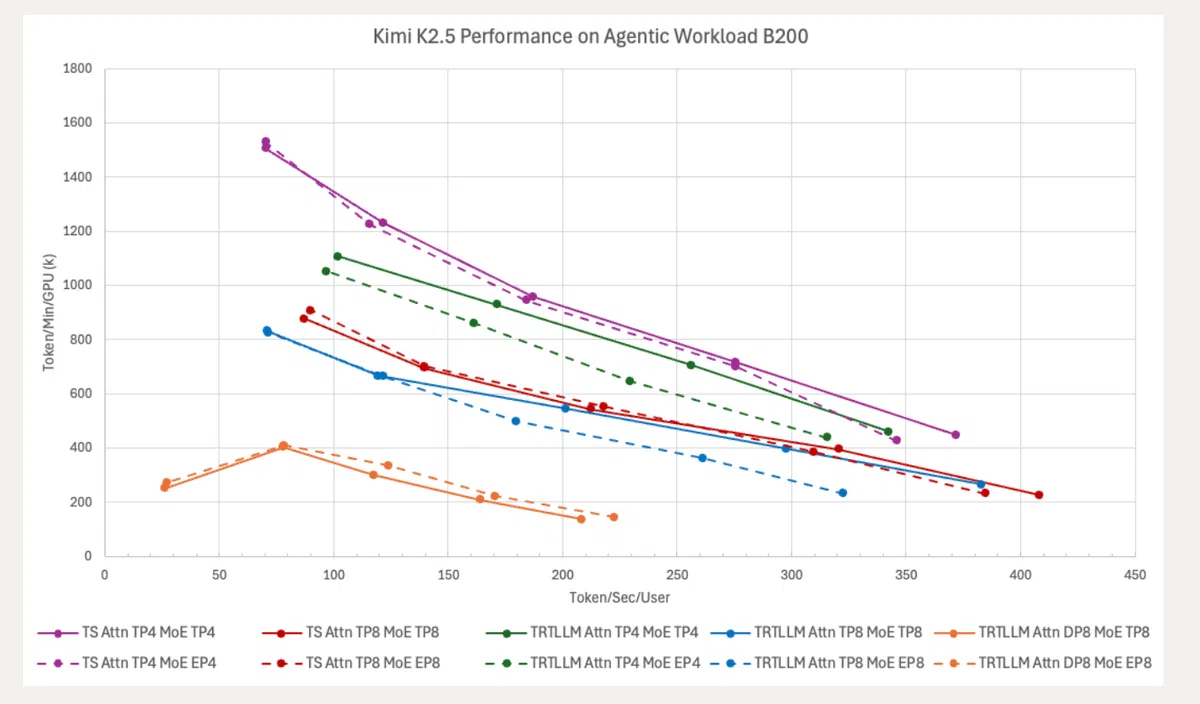
性能基准(对标 TensorRT‑LLM)
- 测试环境:NVIDIA B200(Blackwell),模型 Kimi K2.5,使用 SWE‑smith 真实编码 Agent 流量进行评测。
- 吞吐提升:在 100 TPS/用户的负载下,TokenSpeed 相比 TensorRT‑LLM 提升约 11%,最小延迟(batch=1)提升约 9%。
- 解码阶段优势:MLA 解码内核通过将查询序列轴折叠进 head 轴,使 BMM1 M tile 利用率提升,解码时延几乎减半。
- 预填充优化:二进制预填充内核在长前缀 KV 缓存场景下全面超越 TensorRT‑LLM,尤其在 batch=4/8/16 的投机解码配置下表现突出。
"TokenSpeed 的设计从根本上把 KV 缓存的安全性搬到编译期,而不是运行时约定,这在大规模 Agent 服务中意义重大。"——LightSeek 技术博客
业界意义
- 开源可商用:MIT 许可证让企业可以直接在生产环境中使用、二次改进,无需额外授权费用。
- 跨硬件生态:插件化内核层为未来的 AMD、Intel 加速器预留了接口,降低了对单一 GPU 供应商的依赖。
- 加速 Agent 落地:在编码、调试、自动化测试等高并发场景下,TokenSpeed 的 TPS 与延迟优势直接提升了用户体验与资源利用率。
- 生态兼容:已被 vLLM 集成,意味着现有基于 vLLM 的部署可以平滑迁移到 TokenSpeed,获得性能红利。
获取方式
TokenSpeed 目前处于 preview 阶段,代码与文档已在 GitHub 公布,欢迎开发者下载体验并提交 Issue。详细技术细节与基准报告请参阅 LightSeek 官方博客(https://lightseek.org/blog/lightseek-tokenspeed.html)。
*本文基于 LightSeek 官方发布及 MarkTechPost 报道整理。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。