Meta AI推出NeuralBench开源框架,统一评测36项EEG任务
背景与动机
神经AI(NeuroAI)近年来快速发展,研究者将自监督、语言模型等技术迁移到脑信号上,尝试构建脑基础模型。然而评测生态极度分散:不同团队使用各自的预处理流水线、数据集和任务集合,导致难以判断模型的真实泛化能力。Meta AI团队基于此痛点,推出NeuralBench,提供统一的基准平台,力图建立统一的评价标准。
框架核心组件
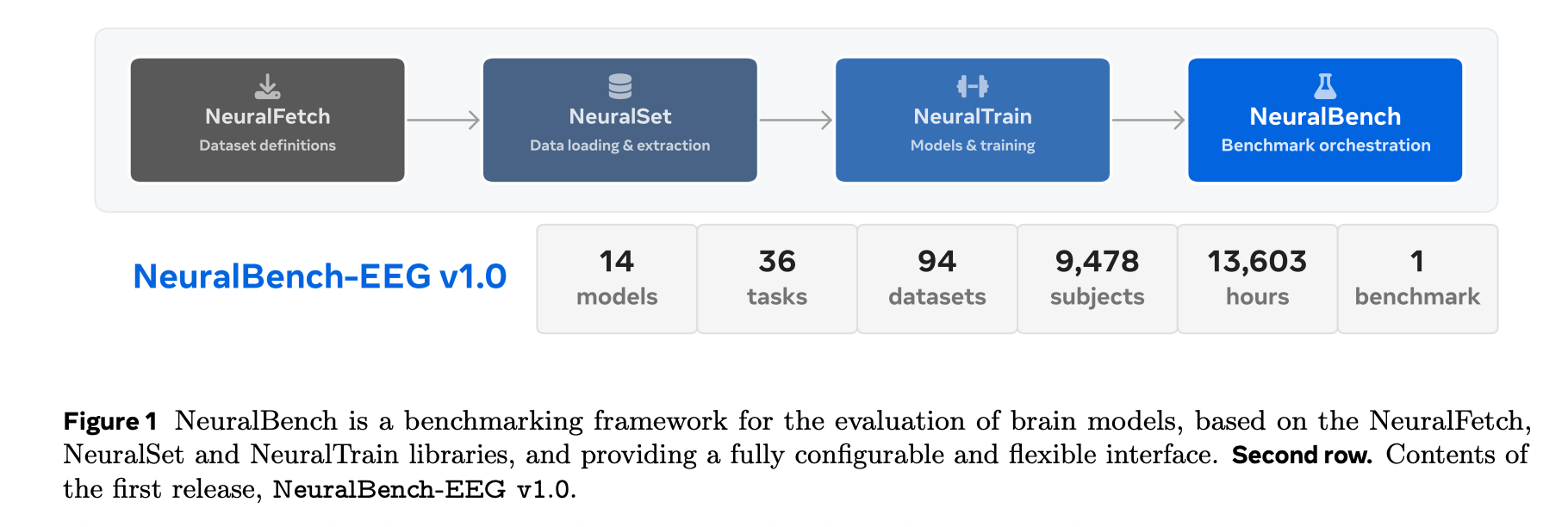
NeuralBench由三大 Python 包组成:
- NeuralFetch:从 OpenNeuro、DANDI、NEMAR 等公共仓库自动下载并管理原始 EEG 数据。
- NeuralSet:基于 MNE‑Python、nilearn 与 HuggingFace,将原始信号包装成 PyTorch DataLoader,支持图像、语音、文本刺激的嵌入提取。
- NeuralTrain:封装 PyTorch‑Lightning、Pydantic 等工具,提供统一的训练、缓存与日志接口。用户仅需三条 CLI 命令即可完成下载、预处理和任务运行,所有配置均通过轻量 YAML 文件声明。
NeuralBench‑EEG v1.0 覆盖范围
首个版本聚焦 EEG,包含八大任务类(认知解码、BCI、诱发响应、临床、内部状态、睡眠、表型、其他),共计36个下游任务,覆盖94个公开数据集,涉及 9,478 名受试者、13,603 小时的记录。评测模型分为三类:
- 任务专用模型(如 ShallowFBCSPNet、EEGNet 等)
- EEG 基础模型(如 BENDR、LaBraM、REVE 等)
- 手工特征基线(SPD 矩阵 + 线性回归)
所有模型均使用统一的超参数配置(AdamW、学习率 1e‑4、余弦退火等),仅在 BENDR 上做了微调,以排除优化技巧对结果的影响。评估指标依据任务类型统一为平衡准确率、Macro‑F1、Pearson 相关或 Top‑5 检索准确率,并进一步转化为归一化得分 s̃,便于跨任务比较。
两大关键发现
- 基础模型优势有限:参数最高的 REVE(69.2M)仅以 0.20 的归一化排名领先,多个轻量任务专用模型(如 150K 参数的 CTNet)紧随其后,说明在当前数据规模下,预训练的 EEG 基础模型并未显著超越从零训练的专用模型。
- 部分任务仍极其困难:图像、语音、视频等认知解码任务的最高得分仍远低于天花板,尤其是精神想象、睡眠觉醒及精神病理解码等任务几乎达到随机水平;而 SSVEP 分类、癫痫检测等已接近饱和,成为未来模型的对照基准。
值得注意的是,虽然 REVE 仅在 EEG 上预训练,却在 MEG 的打字解码任务中取得最佳表现,暗示跨模态迁移的潜在可能。
使用指南
pip install neuralbench
neuralbench eeg audiovisual_stimulus --download # 下载数据
neuralbench eeg audiovisual_stimulus --prepare # 生成缓存
neuralbench eeg audiovisual_stimulus # 运行任务
完整运行 36 项任务约需 11 TB 存储、单卡 32 GB 显存,整体算力消耗约 1,751 GPU‑hour。框架采用 MIT 许可证,代码和详细文档已在 GitHub 公布,欢迎社区贡献新数据集或模型。
行业意义
NeuralBench 为神经AI提供了首个大规模、统一且可扩展的评测基准,解决了长期以来的碎片化难题。它不仅帮助研究者快速复现和对比新模型,也为未来的脑‑计算基础模型提供了标准化的验证平台,预计将在脑机接口、临床诊断和认知科学等多领域产生深远影响。
如需获取更多细节,请访问 Meta AI 官方发布页面或 GitHub 仓库。