Meta AI发布GCM工具提升GPU集群监控,保障大模型训练可靠性
•20 阅读•3分钟•开源
MetaGPUOpenTelemetryGCMSlurm
•20 阅读•3分钟•开源
背景
随着大模型参数突破万亿量级,训练所需的GPU集群规模已从百卡跃升至数千卡。硬件在长时间满负荷运行时,常出现“沉默失效”——GPU表面上仍保持在线,但性能下降、温度异常或出现XID错误,导致梯度污染甚至训练崩溃。传统的系统监控只能提供整体功耗或利用率,难以定位具体节点问题。
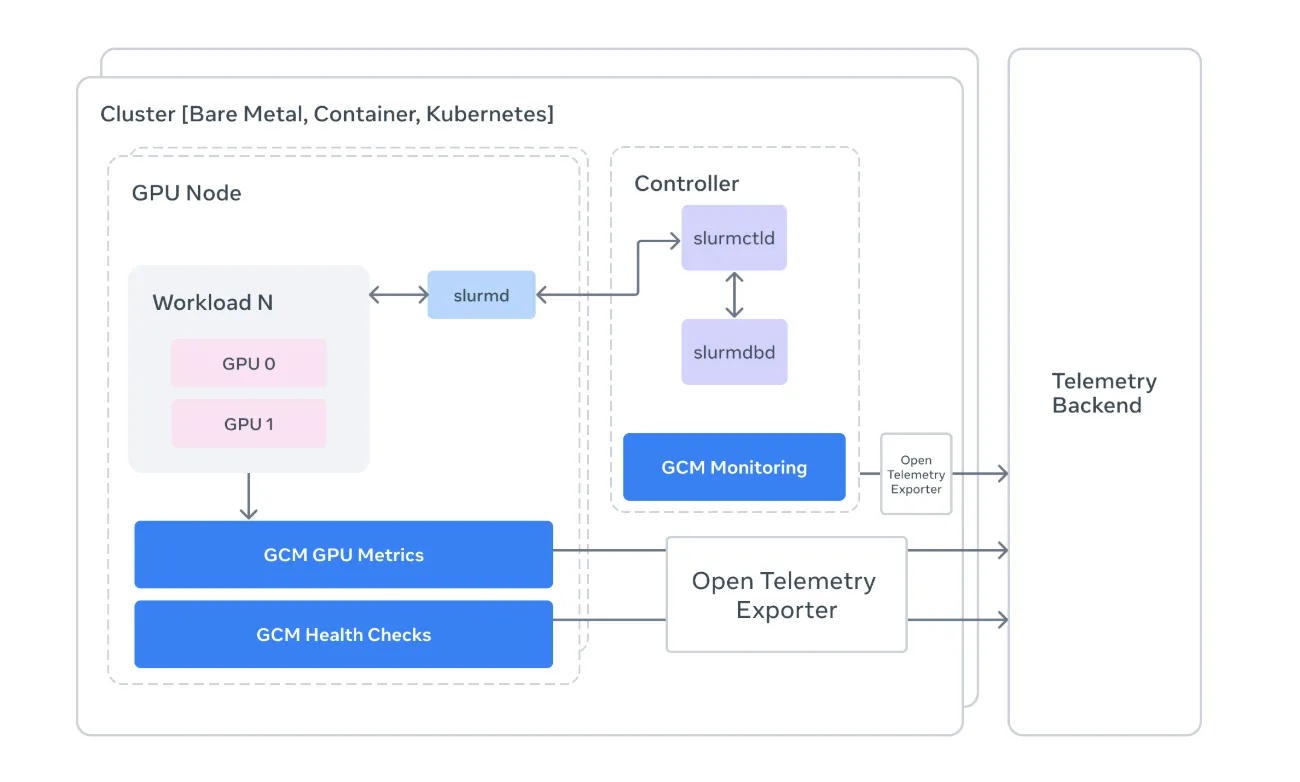
核心功能
- Slurm 深度集成:直接读取
sacct、sinfo、squeue,实现作业级别的指标归属,帮助运维人员快速定位是哪一次训练作业导致异常。 - Prolog 与 Epilog 检查:在作业启动前执行硬件健康预检(网络、GPU 可达性),启动后利用 NVIDIA DCGM 进行深度诊断,自动将异常节点标记为 DRAIN。
- OTLP 统一遥测:将 GPU 温度、NVLink 错误、XID 事件等低层数据转化为 OpenTelemetry(OTLP)格式,可无缝接入 Prometheus、Grafana 等可观测平台。
- 模块化 Collector‑Sink 架构:Python 编写的采集器负责从
nvidia‑smi、NVML 等获取原始数据,Go 实现的高性能 Sink 支持本地调试、标准输出以及 OTLP 推送。
技术实现
GCM 项目代码仓库约94% 为 Python,保持了对科研团队的易用性;关键路径使用 Go 以降低采集延迟。核心组件包括:
- Collector:基于 NVIDIA Management Library (NVML) 直接读取硬件状态,避免高层抽象掩盖错误。
- Sink:提供多种输出后端,默认通过 OTLP 将数据发送至统一的可观测系统。
- Health Check Engine:在 Prolog/Epilog 阶段调用 DCGM,生成详细的硬件健康报告并写入 Slurm 作业日志。
业界意义
- 提升训练可靠性:通过提前剔除故障节点,显著降低因硬件异常导致的训练中断或梯度偏差。
- 降低运维成本:细粒度的作业‑GPU 关联数据帮助数据中心在数千卡规模下实现精准排障,避免人工盲目排查。
- 推动标准化监控:采用 OTLP 统一格式后,AI 研发团队可以将硬件遥测与业务指标同等对待,实现“一站式”可观测。
结论
Meta AI 将 GCM 以 Apache 2.0 开源,提供完整文档与示例,旨在帮助科研机构和企业级算力平台快速落地高可靠性的硬件监控方案。随着大模型训练规模继续扩大,类似 GCM 的基础设施工具将成为保障 AI 研发效率的关键支撑。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。