NVIDIA推出Dynamo Snapshot实现Kubernetes AI推理秒级启动
•0 阅读•5分钟•视野
NVIDIAvLLMKubernetesDynamo Snapshot
•0 阅读•5分钟•视野
背景
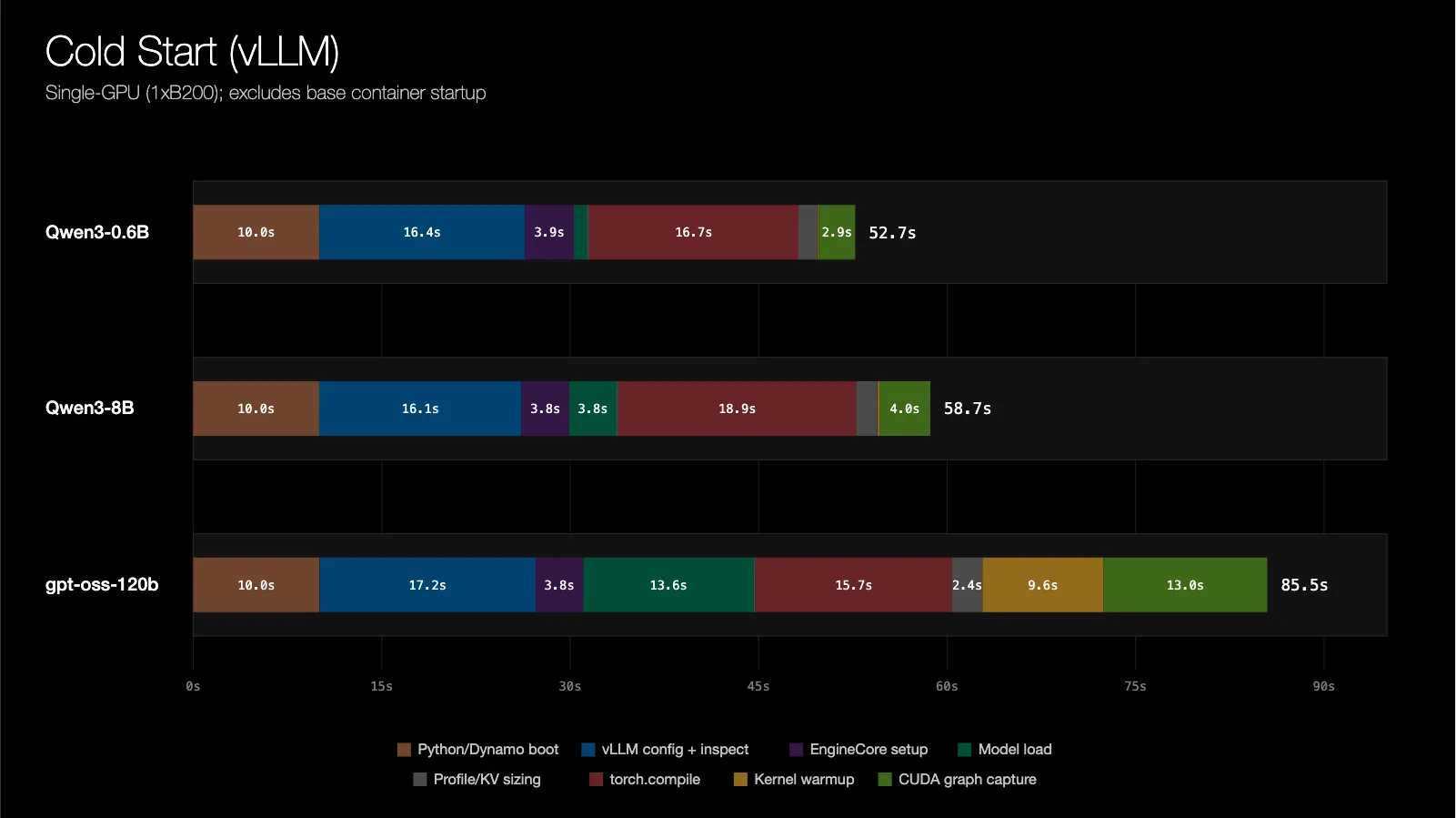
在生产环境中,AI 推理服务的副本需要根据请求量弹性伸缩。传统的 Kubernetes 部署在新增副本时,需要经历镜像拉取、模型权重加载、CUDA 内核预热、图编译以及服务发现等步骤,整个冷启动过程往往耗时数分钟,导致 GPU 资源空闲且易触发 SLA 违约。
Dynamo Snapshot 工作原理
Dynamo Snapshot 采用 checkpoint/restore 思路,将运行中的推理工作进程完整冻结后保存,再在需要时快速恢复。其核心工具有两种:
- cuda‑checkpoint:利用 CUDA 驱动的检查点功能,把 GPU 侧的上下文、流、显存以及虚拟地址映射导出到 CPU 内存。
- CRIU(Checkpoint/Restore in Userspace):遍历 Linux 内核的进程树,将 CPU 侧的内存、线程、文件描述符等状态序列化到磁盘。
在 checkpoint 阶段,先执行 cuda‑checkpoint 导出 GPU 状态,再由 CRIU 把主机进程状态写入共享存储;恢复时则先让 CRIU 重建进程树,随后 cuda‑checkpoint 将 GPU 状态重新注入新节点的显卡。
关键技术细节
- 容器级别检查点:Dynamo Snapshot 通过 Helm 安装的 privileged DaemonSet(snapshot‑agent)在每个节点上拦截 runc 容器,实现无需修改容器运行时即可完成检查点。
- Quiesce/Resume Hook:推理工作在 引擎初始化 完成后、分布式运行时启动 之前写入 “ready for checkpoint” 信号文件,随后进入轮询等待恢复完成的状态,实现无缝切换。
- KV Cache 虚拟化:利用 CUDA 虚拟内存 API(cuMemCreate、cuMemMap)分配 KV 缓存并在 checkpoint 前通过 cuMemUnmap/cuMemRelease 释放物理显存,仅保留虚拟地址,显著压缩检查点体积(Qwen3‑0.6B 从约190 GiB 降至 6 GiB)。
- CRIU 优化:
- 并行 memfd 恢复:将多个共享匿名内存块并行恢复,提升 I/O 利用率。
- Linux 原生 AIO:使用 io_submit、io_getevents 实现最高 128 条并发读,配合 O_DIRECT 减少页缓存压力。
- GPU Memory Service(GMS):将模型权重从进程检查点中剥离,独立存储并通过 GPUDirect Storage 或 NVLink 并行恢复,实现权重与进程状态的同步恢复。
性能提升与实验数据
| 模型 | 检查点大小 | CRIU(原版)恢复时间 | AIO + 并行 memfd | 加速比例 |
|---|---|---|---|---|
| Qwen3‑0.6B | 6.2 GiB | 6.8 s | 2.4 s | 2.8× |
| Qwen3‑8B | 26 GiB | 24 s | 4.7 s | 5.1× |
| gpt‑oss‑120b | 129 GiB | 119 s | 15 s | 7.9× |
在加入 GMS 后,gpt‑oss‑120b 的整体启动时间降至 5 秒以内,相当于传统冷启动的 1/21,实现了秒级弹性扩容。
部署与限制
- 前置条件:x86_64 GPU 节点、NVIDIA 驱动 580.xx+(多 GPU 需 590.xx+)、ReadWriteMany 存储、仅支持 vLLM(预览版)。
- 自定义资源:
DynamoCheckpoint(标识模型、框架、并行度等)与DynamoGraphDeployment用于引用检查点进行恢复。 - 当前局限:不支持多模态、嵌入、扩散等专用工作负载;多 GPU 张量并行仍在验证中;GMS 仍为实验特性,需自行开启。
业界意义
Dynamo Snapshot 为 AI 推理的弹性伸缩提供了硬件层面的“冷启动”解决方案,降低了 GPU 空转成本,也为云原生 AI 平台的高可用设计提供了新思路。随着 CRIU 与 GMS 的进一步成熟,预计未来将扩展至多节点、跨云环境的快速迁移,为生成式 AI 服务的规模化部署奠定基础。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。