Harness-1登场 20B检索子代理凭状态化搜索框架刷新召回纪录
•2 阅读•3分钟•前沿
ChromaUniversity of Illinois Urbana-ChampaignGPT-OSS-20BHarness-1
•2 阅读•3分钟•前沿
背景与挑战
当前大多数搜索代理将检索决策与繁琐的记忆、证据管理混合在同一条增长的对话稿本中,导致模型需同时学习何时搜索、如何保存证据以及如何验证结论,训练难度大、性能受限。
Harness-1 核心设计
- 状态化搜索框架:框架负责所有 bookkeeping,包括候选池、重要度标记的精选集、证据图、验证记录等;策略模型仅输出结构化动作(如
search_corpus、verify)。 - 认知卸载:将“记忆”外包给环境,策略只专注语义层面的搜索与筛选。
- 工具集合:八个工具覆盖从全局搜索、正则抽取到文档阅读、结果验证的完整流程。
- 精选集上限:最多 30 篇文档,按四级重要度(very_high、high、fair、low)标记。
训练方法与实现
- 监督微调 (SFT):使用 899 条人工标注轨迹,教师模型为 GPT‑5.4,LoRA rank‑32,训练 3 轮。
- 强化学习 (RL):在完整框架内进行 on‑policy CISPO 训练,奖励仅在回合结束时给出,包含发现奖励、选择奖励以及工具多样性奖励。
- 数据规模:共 4 352 条独特训练样本(SFT 899 条 + RL 3 453 条),使用 Tinker 集群完成。
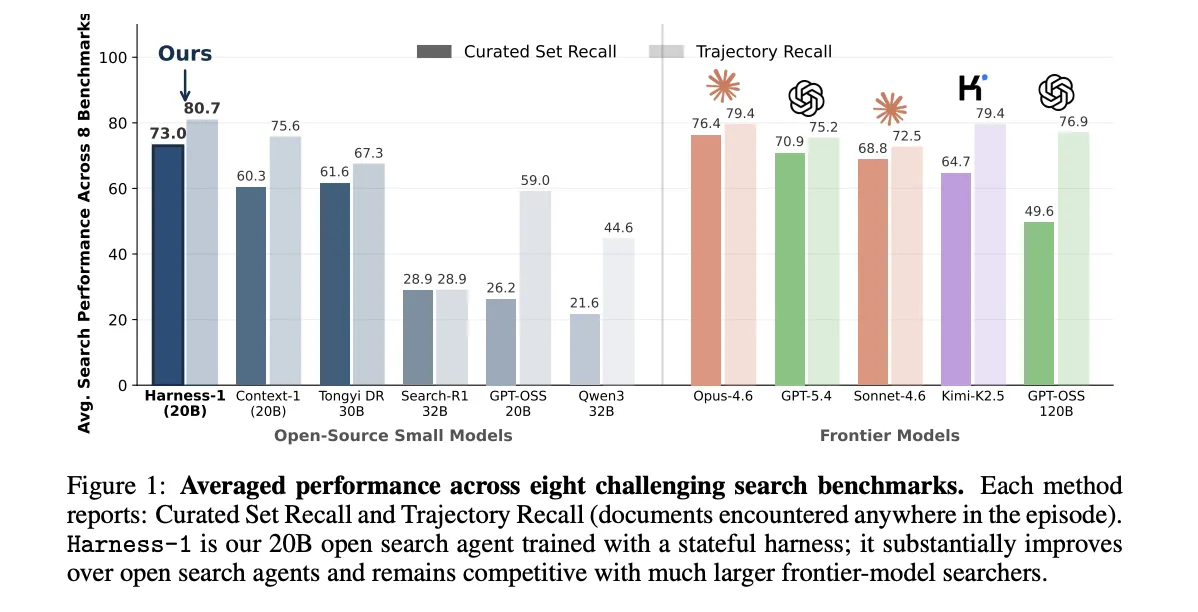
基准评估与对比
| 模型 | 平均 curated recall | 平均 trajectory recall |
|---|---|---|
| Harness‑1 (20B) | 0.730 | 0.807 |
| Tongyi DeepResearch 30B | 0.616 | 0.673 |
| Opus‑4.6 (Frontier) | 0.764 | 0.794 |
- 在八大公开基准(网页、金融、专利、多跳 QA)上,Harness‑1 超过下一个开源基线 11.4 分。
- 对于与训练分布最不相似的四个持出基准,提升高达 17.0 分,显示强迁移能力。
- Ablation 实验表明,去除全部框架机制会导致召回下降约 12.2%。
开源与应用前景
- 权重 & 代码:已在 Hugging Face(
pat-jj/harness-1)公开,兼容 vLLM、SGLang 与 Transformers。 - 典型场景:文献/专利审阅、金融报表分析、多跳事实核查以及模块化 RAG,均可利用其结构化的证据图与精选集提升下游生成模型的答案准确率。
- 局限:证据图依赖正则抽取,缺乏完整实体链接;验证工具为 LLM 代理,仍会出现歧义误判。
Harness‑1 的出现标志着检索代理在“认知卸载”方向的首次大规模实证,为后续开放式搜索系统提供了可复现的基线与开源资源。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。