AWS发布全栈基座模型训练推理平台 助力大模型高效扩展
•43 阅读•5分钟•视野
NVIDIAAmazonGPUH100EFA
•43 阅读•5分钟•视野
背景与趋势
随着大模型规模突破千亿参数,单纯提升算力已难以满足性能需求。NVIDIA 提出的“三大 scaling 法则”指出,模型性能已从前训练的算力提升,转向后训练(SFT、RLHF)和推理阶段的算力利用。AWS 在此背景下,围绕 紧耦合加速计算‑高带宽网络‑可扩展存储,构建了统一的基座模型训练与推理平台。
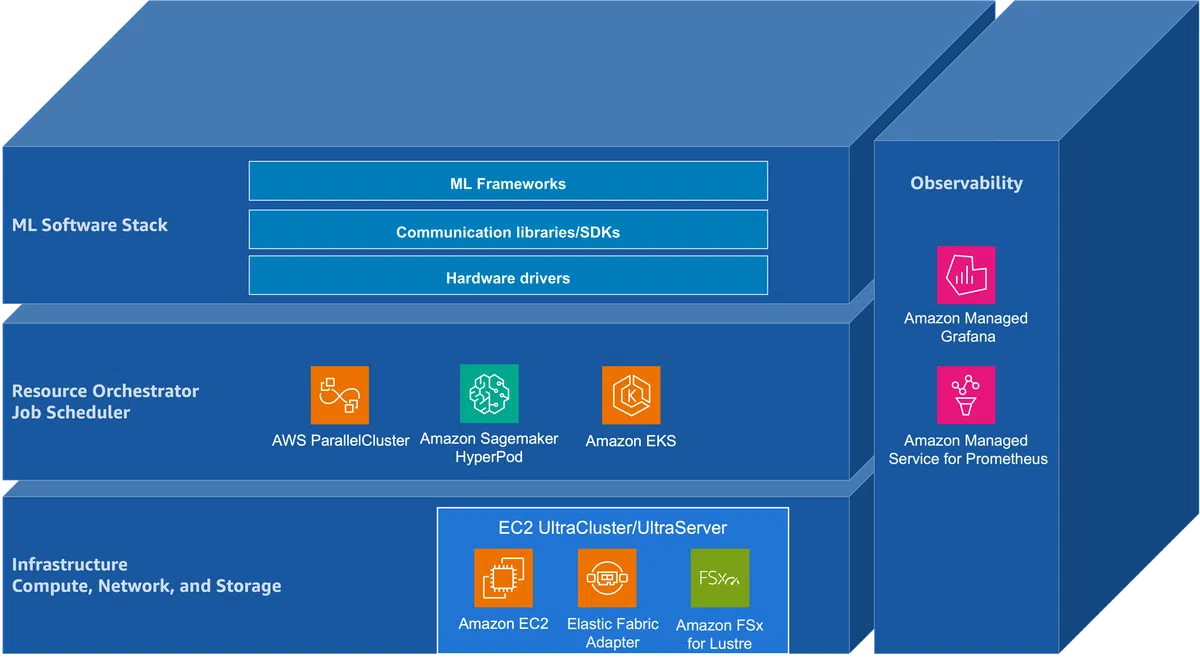
基础设施构建块
- 计算层:提供多代 NVIDIA GPU 实例,核心包括:
- P5 系列:p5.48xlarge 配置 8×H100,p5.4xlarge 为单卡轻量版;
- P6 系列:B200(Blackwell)与 B300(Ultra)分别对应 8×Blackwell GPU,峰值 BF16/FP16 Tensor 吞吐 2.25 PFLOPS,FP8 达 4.5 PFLOPS。
- 网络层:内部采用 NVLink/NVSwitch,实现节点内低延迟上行;跨节点使用 Elastic Fabric Adapter(EFA),已迭代至 v4,带宽提升约 18%,延迟下降 35%。
- 存储层:本地 NVMe SSD(30.72 TB)用于热数据,FSx for Lustre 提供并行共享文件系统,S3 负责长期持久化。多层存储实现数据流的冷热分层,支撑数 TB 级 checkpoint 与数据集的实时加载。
资源编排:Slurm 与 Kubernetes
- Slurm:AWS ParallelCluster 与 SageMaker HyperPod 提供托管式 Slurm 集群,支持原子化的多节点作业调度、拓扑感知的 NVLink/EFA 配置以及 GPU 资源的 GRES 管理。
- Kubernetes:通过 EKS + NVIDIA device plugin 实现 GPU 调度;Kueue、Volcano 与 NVIDIA KAI Scheduler 为大模型训练提供 gang‑scheduling 与拓扑感知的调度策略,配合 SageMaker HyperPod 的弹性伸缩与节点即时供给(Karpenter)。
完整的机器学习软件栈
- 硬件驱动:NVIDIA GPU 驱动、GDRCopy、EFA、Lustre 客户端。
- 运行时与库:CUDA 13.x(Blackwell 支持),CUTLASS、CuTe、Triton 用于自定义高效算子(如 FlashAttention、FP8 GEMM)。
- 通信子层:NCCL 通过 aws‑ofi‑nccl 插件对接 EFA,实现跨节点的 ring/tree 集体通信;NIXL 负责推理阶段的点对点 KV‑cache 迁移。
- 框架层:PyTorch + torch.distributed(DDP、FSDP2)为主流开发环境。
- 分布式训练/推理框架:
- Hugging Face Transformers(Trainer + Accelerate)适用于中等规模微调;
- NVIDIA Megatron‑Core 与 NeMo 面向千卡以上的 3D 并行;
- vLLM、SGLang 为推理提供 PagedAttention、RadixAttention 等高效缓存管理。
可观测性体系
- 指标采集:DCGM‑Exporter 暴露 GPU 利用率、HBM 带宽、ECC 错误;EFA 驱动输出网络吞吐与重传统计;FSx for Lustre 提供文件系统 I/O 指标。
- 监控平台:Amazon Managed Service for Prometheus(AMP)与 Amazon Managed Grafana(AMG)实现统一的时序数据库与可视化仪表盘,支持自定义告警(GPU XID、温度、网络抖动)。
- 故障预警:通过 GPU Health‑Cluster 仪表盘监测 ECC 与 XID 事件,实现硬件预失效检测,降低长时间训练作业的意外中断风险。
影响与展望
AWS 的四层架构实现了从硬件到业务层的全链路协同,为研发团队在 预训练‑后训练‑推理 三阶段提供统一的性能基准与成本模型。随着模型参数继续攀升,算力、网络、存储的协同优化将成为关键,AWS 已通过 UltraServer 与 Blackwell 超芯片进一步压缩 CPU‑GPU‑内存的访存距离,为未来的 具身智能 与 多模态大模型 奠定基础。
“在大模型时代,基础设施的统一抽象才是提升研发效率的根本。” — AWS 基础模型技术团队
未来,AWS 计划在此框架上加入更细粒度的 自动化调优 与 跨云混合部署 能力,以满足多租户、跨地域的弹性算力需求。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。