NVIDIA推出Polar框架 让代码Agent强化学习零改动跨平台
背景与挑战
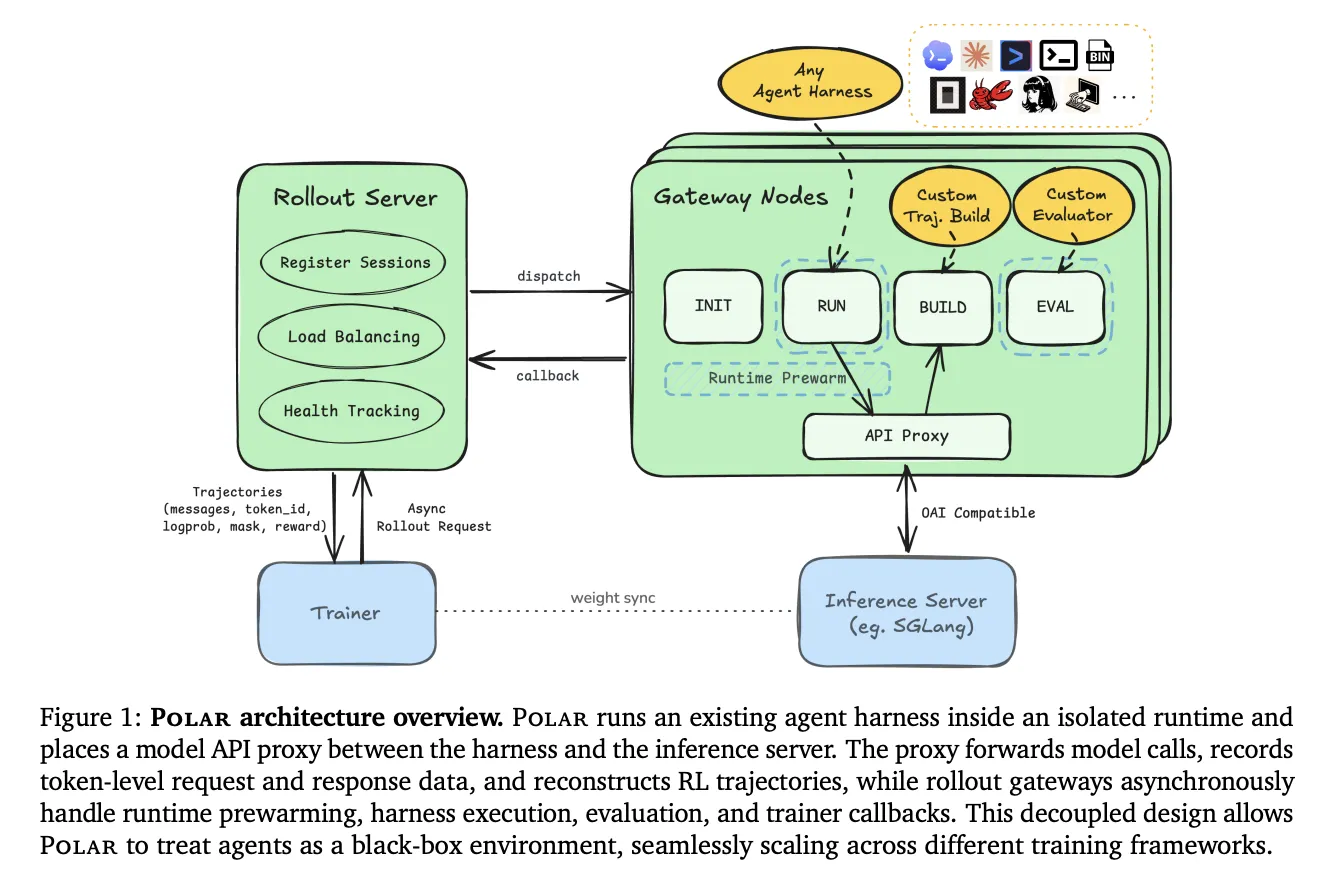
随着大语言模型在代码生成、工具调用等场景的广泛落地,Agent的多轮交互与复杂工具链已成为研发热点。然而,传统强化学习(RL)框架需要将Agent的 harness(如Codex CLI、Claude Code、Qwen Code)重新封装为Gym‑style 环境,导致大量重复的集成工作,并且常常丢失原生的提示、工具格式等细节,影响评估效果。
Polar框架核心设计
Polar的核心思路是:所有LLM‑based Agent 必然会调用一次模型 API。框架在模型调用入口部署 代理层(proxy),拦截并记录每一次 token‑level 交互,然后按需重构为训练可用的轨迹。这样,研究者只需把原有 harness 的模型基地址指向 Polar 提供的网关,即可完成 RL 训练,无需改动任何业务代码。
- 跨平台兼容:自动识别 Anthropic、OpenAI、Google 三大主流 API 格式。
- 统一数据模型:将请求统一转为 OpenAI Chat‑Completions 结构,便于本地推理服务器统一处理。
- 完整 token 捕获:记录请求/响应消息、prompt 与采样 token ID、结束原因及 log‑prob,确保奖励信号精准对应实际生成过程。
- 流式兼容:对原生流式请求返回合成的 provider‑shaped 流,保持 harness 对 SSE 的期待。
关键技术细节
- Rollout Server 与 Gateway 节点:Rollout Server 接收 TaskRequest,拆分为多并行会话;每个 Gateway 负责会话生命周期,包括 runtime 启动、harness 执行、轨迹构建、评估回调。
- 两种轨迹构建策略
- per_request:每一次模型调用单独存为一条轨迹,保证无损但会产生大量碎片。
- prefix_merging:依据 token 前缀关系合并连续调用,生成更长的完整轨迹,显著减少 trainer 更新次数。
- 内置评估器:包括会话完成奖励、基于输出的测试评估以及 SWE‑Bench/SWE‑Gym 专用评估器,均可通过注册表自行扩展。
- 运行时支持:兼容 Docker 与 rootless Apptainer,提供 codex、claude_code、gemini_cli、qwen_code、opencode、pi 等常用 harness 快捷入口。
实验结果与性能提升
使用 GRPO 在 Qwen3.5‑4B 基模型上进行 SWE‑Bench Verified 任务的实验显示:
- Codex harness:成绩从 3.8% 提升至 26.4%,净增 22.6 分。
- Claude Code:提升 4.8 分,达到 34.6%。
- Qwen Code:微增 0.6 分。
- Pi harness:提升 6.2 分。
在轨迹构建上,prefix_merging 将 trainer 更新次数从 1,185 降至 218,整体训练时长从 189.5 分钟压缩至 35.2 分钟,GPU 利用率提升至 87.7%,实现约 5.4 倍 的加速。
开源与生态
Polar 已在 GitHub(github.com/NVIDIA‑NeMo/ProRL‑Agent‑Server)以 Apache‑2.0 许可证发布,并注册为 NeMo Gym 环境,社区可直接通过 pip 安装并在现有代码库上实验。框架提供详细的 Dockerfile 与 Apptainer 镜像,支持一键部署多节点 rollout 服务。
影响与展望
Polar 的推出让研发人员能够快速在任意代码agent上开展强化学习实验,降低了集成成本并保留了原生执行细节,为下一代具备工具使用与自我改进能力的编码助手奠定了基础。未来工作将聚焦于奖励函数设计、评估器质量提升以及跨模型分布迁移的稳健性研究。
“通过在模型 API 层拦截,我们实现了真正意义上的 ‘无侵入式’ 强化学习”,—— NVIDIA 研究团队