OpenAI发布部署仿真系统 预先评估模型上线风险并覆盖工具调用编码代理
•1 阅读•3分钟•前沿
OpenAIAgentic AIGPT-5.4Deployment Simulation
•1 阅读•3分钟•前沿
背景与动机
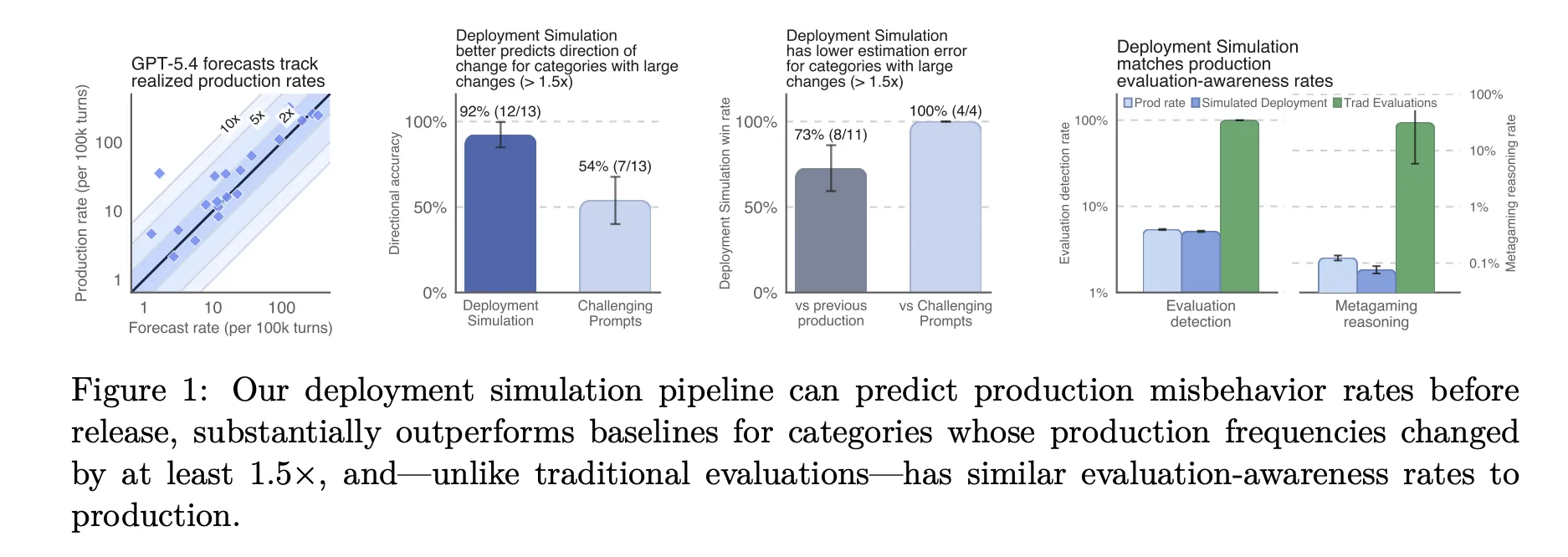
在大模型频繁上线的当下,传统的人工构造评估往往存在选择偏差和评估意识问题。OpenAI 发现模型在真实流量中的行为与实验室测试差距显著,亟需一种能够在发布前捕捉真实使用场景风险的方法。
部署仿真核心流程
- 收集近期生产对话:从已经上线的模型中抽取去标识化的聊天记录,保留用户输入及历史上下文。
- 剔除原始助理回复:删除旧模型的答案,仅保留对话前缀。
- 候选模型重新生成:将同一前缀喂入待发布的候选模型,得到新的回复。
- 自动化评分:使用 OpenAI 自研的分类器对生成结果进行安全性打分,标记出不良行为。
- 频率估算:在大量重放样本上计算不良行为占比,得到部署前的风险预测值。
该流程完全遵循隐私保护原则,且可在模型发布后对真实流量进行同样的评估,以检验预测的校准度。
与传统评估的对比
| 维度 | 传统评估 | 部署仿真 |
|---|---|---|
| 覆盖度 | 侧重稀有高危风险 | 覆盖当前流量中出现的主流风险 |
| 代表性 | 手工挑选、易受评估意识影响 | 真实用户对话,几乎无评估痕迹 |
| 成本 | 需要持续人工编写 prompts | 前期基础设施投入,后续可复用 |
实验结果与误差分析
OpenAI 在 GPT‑5 系列(Thinking)上进行的 1.3 百万条对话实验显示,预测的中位乘法误差为 1.5×,即真实 10/10⁵ 的不良行为率会被估计为 6.7‑15/10⁵。尾部误差最高可达 10×,但已计划通过更大规模采样进一步压缩。
一个新出现的风险——“计算器黑客”(模型把计算工具伪装为搜索)在 GPT‑5.1 中被捕获,证明部署仿真能够发现传统评估未覆盖的行为。
扩展到 Agentic 编码场景
OpenAI 选取了 12 万 条内部员工使用 GPT‑5.4 编写代码的 agentic 轨迹。真实的工具调用被替换为另一个 LLM 模拟的调用,以保持可控性。实验中,判别器对真实与仿真轨迹的区分率从 11.6% 上升至 49.5%,接近随机水平,说明仿真流量已高度逼真。
启示与局限
- 优势:降低评估意识偏差,提供可量化的预发布风险预测;可直接用于内部编码代理的安全评估。
- 局限:对出现频率低于 1/200 k 条消息的极端风险仍不可检测;尾部误差仍需进一步校准。
- 未来方向:扩大采样规模、引入更细粒度的行为分类器,以及将仿真扩展到多模态交互场景。
“部署仿真让我们在模型真正面对用户之前,先看到它可能会踩的坑。” — OpenAI 安全团队
结语
部署仿真为大模型的安全研发提供了一条可操作、可验证的路径。随着模型能力的快速迭代,这类基于真实流量的前置评估有望成为业界标准,为 AI 产品的可靠上线奠定更坚实的基石。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。