MiniMax发布MSA稀疏注意力模型 大幅降低长上下文计算成本
•3 阅读•4分钟•前沿
MiniMaxMixture-of-ExpertsMSASparse Attention
•3 阅读•4分钟•前沿
背景与动机
长序列推理的计算瓶颈一直是软max注意力的二次增长。MiniMax团队在一篇arXiv论文([2606.13392v1])中提出MSA(MiniMax Sparse Attention),旨在通过块级稀疏化保持注意力质量的同时,将计算成本固定在常数范围。
MSA技术细节
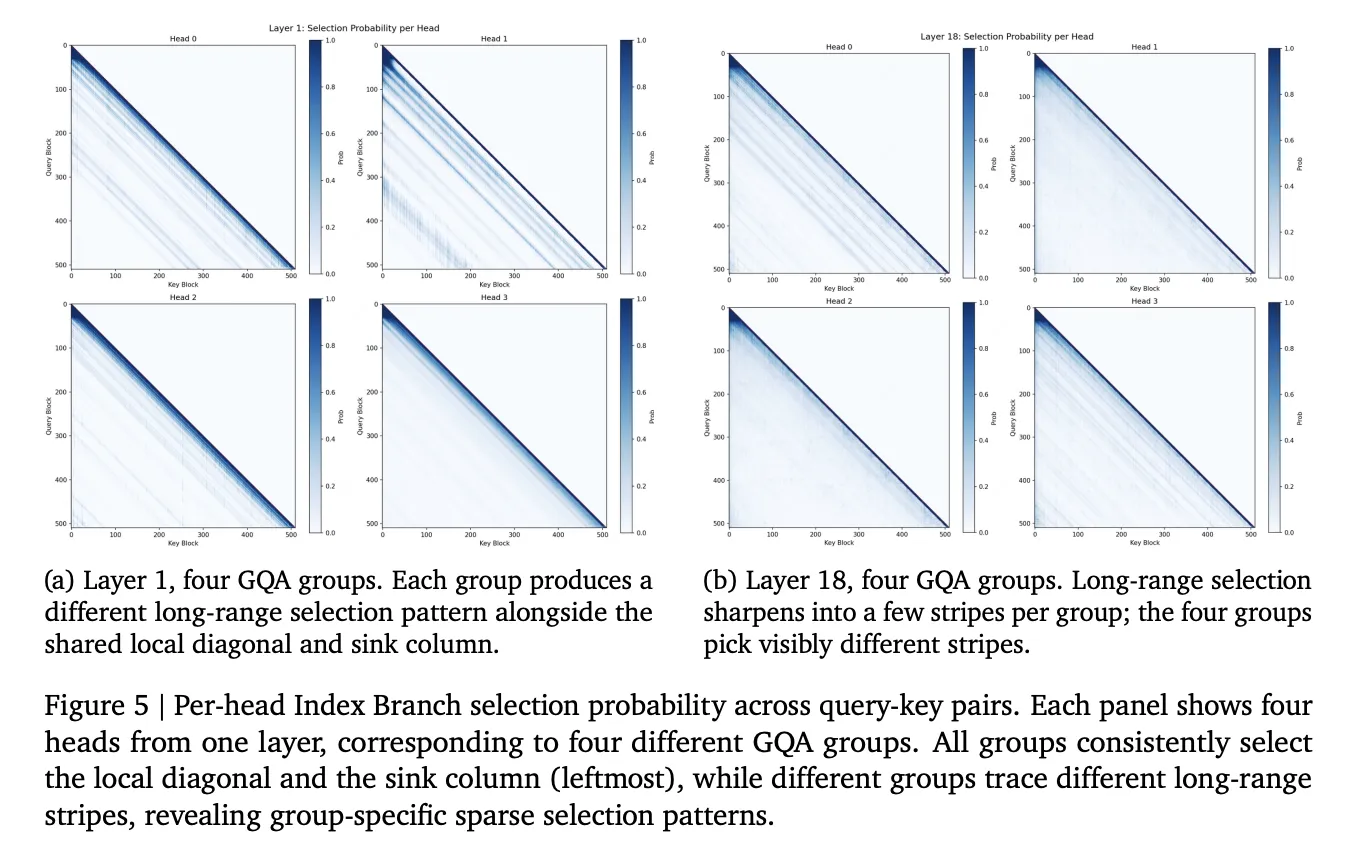
- 双分支结构:
- 索引分支(Index Branch) 负责为每个查询及其所属的GQA组挑选Top‑k块(默认k=16,块大小Bₖ=128),只保留2,048个键值对。
- 主分支(Main Branch) 在选中的块上执行完整的softmax注意力。
- 块级选择:索引分支在每个GQA组内部共享同一套块索引,跨组独立,使得KV读取保持连续性。
- 训练机制:采用KL对齐损失,将索引分支的分布对齐到主分支的注意力模式;配合梯度截断、索引热身等三项技巧保证稀疏训练的稳定性。
训练与评估
MSA在一个拥有1090亿参数、Mixture‑of‑Experts(MoE)结构的多模态模型上进行训练,使用约3T token的数据预算。评测结果显示:
| 数据集 | Full‑Attention | MSA‑PT | MSA‑CPT |
|---|---|---|---|
| MMLU | 67.0 | 67.0 | 66.8 |
| GSM8K | 76.2 | 77.7 | 73.7 |
| HumanEval | 61.0 | 64.0 | 57.9 |
在长上下文基准(HELMET‑128K、RULER‑128K)上,MSA‑CPT仍能紧跟全注意力基线,仅在部分细分任务上出现轻微差距。
开源实现与性能
MiniMax同步发布了针对NVIDIA SM100 GPU的内核库 fmha_sm100,包括:
- 无指数Top‑k:利用softmax保序特性直接在原始分数上做Top‑k,省去exp和归一化步骤,在128K上下文、k=16时比torch.topk快5.1×。
- KV‑outer稀疏注意力:将查询打包进128×128的MMA运算,提高算力利用率;两阶段前向将注意力与合并步骤分配到不同CTA。
该内核支持BF16、FP8、NVFP4、FP4等多种低精度,MIT许可证开源,可通过 pip install -U kernels 直接调用。实测在H800上,预填充加速14.2×,解码加速7.6×。
应用前景与局限
MSA特别适合以下场景:
- 长程推理代理:数百步的行为序列可保持固定的查询预算。
- 代码库级检索:完整代码库的数十万token可快速定位相关块。
- 持久记忆助手:对话历史随时间增长,仍能以固定成本读取最相关片段。
- 长视频理解:多模态模型在视频帧序列上保持竞争力。
然而,当前实现仅针对SM100 GPU,其他硬件需自行移植;在部分细分任务上仍存在检索差距;KL对齐的额外损失增加了训练复杂度。后续需要更多第三方复现以验证其通用性。
MiniMax 表示,MSA 为“在保持模型表达力的前提下,实现长上下文高效推理的可行路径”。
结语
随着大模型上下文长度不断突破,稀疏注意力方案将成为主流技术选项。MSA 通过块级索引、两分支协同以及高效GPU内核,为业界提供了一个兼具学术新颖性和工程落地性的完整生态。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。