NVIDIA发布Gated DeltaNet-2 线性注意力层实现擦除写入解耦显著提升长上下文检索
•92 阅读•4分钟•前沿
NVIDIAGated DeltaNet-2线性注意力长上下文检索
•92 阅读•4分钟•前沿
背景
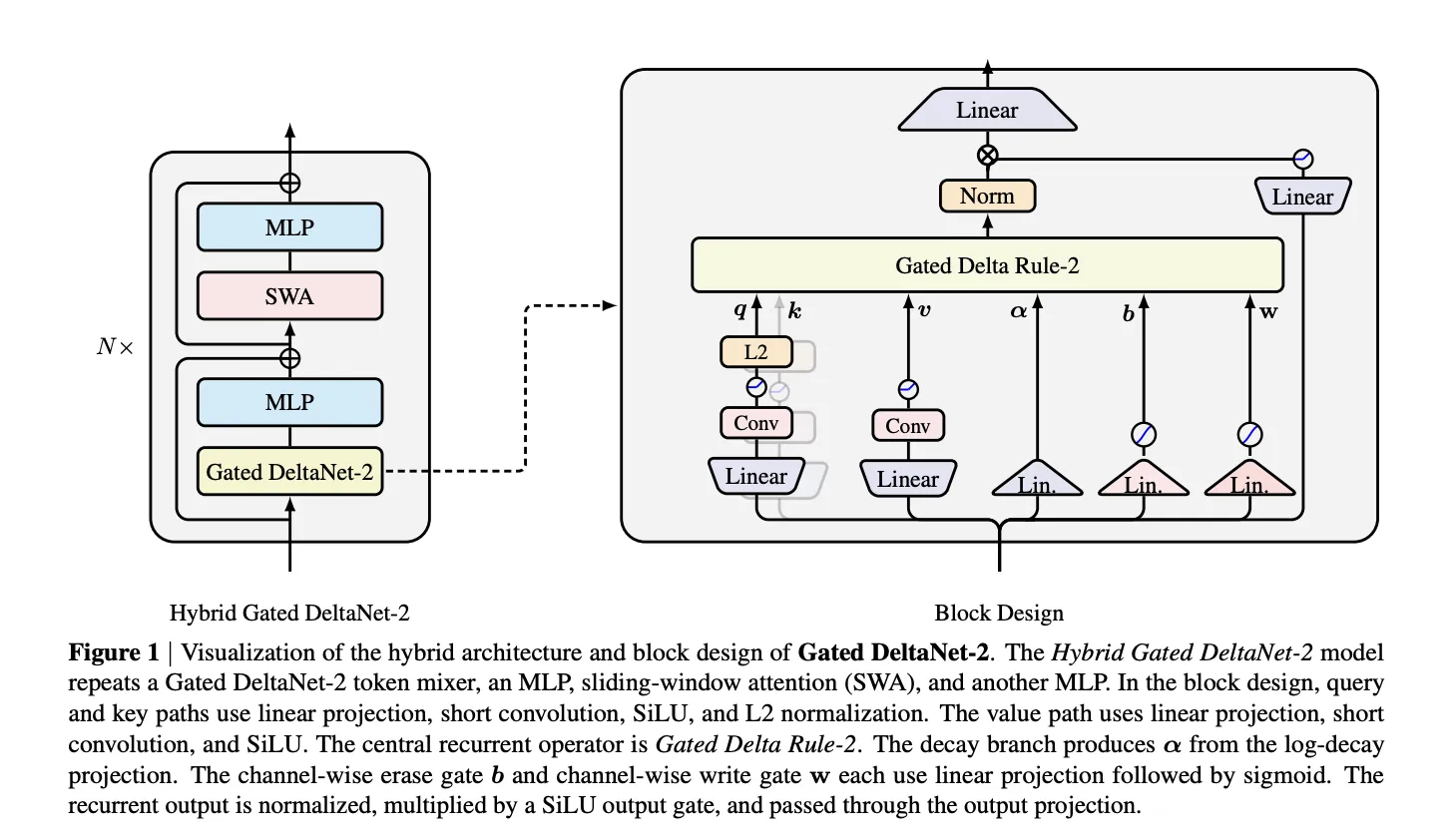
线性注意力通过将无界 KV 缓存压缩为固定大小的递归状态,实现了 (O(n)) 的序列混合和常数显存占用。然而,如何在不破坏已有关联的前提下编辑这段压缩记忆,一直是该范式的瓶颈。此前的 Delta‑Rule 系列(Gated DeltaNet、KDA)采用单一标量门 (\beta_t) 同时控制擦除旧内容和写入新内容,导致模型表达受限。
技术创新
Gated DeltaNet-2 将这一标量门拆分为两组通道级向量:
- 擦除门 (b_t \in [0,1]^{d_k}):作用于键(key)轴,决定哪些记忆通道被衰减后删除。
- 写入门 (w_t \in [0,1]^{d_v}):作用于值(value)轴,挑选新信息写入的通道。
更新公式为:
S_t = (I - k_t (b_t \odot k_t)^ op) D_t S_{t-1} + k_t (w_t \odot v_t)^ op
其中 (D_t = ext{Diag}(\alpha_t)) 为 KDA 继承的通道级衰减矩阵。该设计在保持 Delta‑Rule 写入方向的同时,使读写过程在不同轴上实现细粒度选择,显著提升记忆编辑的灵活性。
训练与实验设置
- 模型规模:1.3 B 参数
- 训练数据:100 B FineWeb‑Edu tokens
- 递归状态大小:每层 262,144 浮点数(与 Mamba‑2/3 对齐)
- 序列长度:4 K(递归)/ 2 K(混合模式)
- 优化器:AdamW,学习率 4e‑4,余弦调度,1 B token 预热
- 实现:基于 PyTorch 与 Triton 的 fused WY 前向/反向内核,chunk 大小 64
评测成绩
| 设定 | LAMBADA+推理平均 | 长上下文检索 S‑NIAH-3 (2K) | 实际检索 Recall 平均 |
|---|---|---|---|
| Gated DeltaNet‑2(递归) | 53.11 | 89.0 → 93.0 | 28.67 → 29.88 |
| Gated DeltaNet‑2(混合) | 53.97 | 63.2 → 89.8 | 40.14 → 42.28 |
相较于 Mamba‑3、KDA 等基线,Gated DeltaNet‑2 在所有评测中均实现正向提升,尤其在 RULER 长上下文检索任务上提升超过 30%。
业界影响
- 模型压缩:在保持相同状态容量的前提下,解耦门带来的性能提升表明线性注意力仍有显著优化空间。
- 长序列推理:混合块结构(递归 + Sliding‑Window Attention)兼顾全局记忆压缩与局部交互,为 10K‑以上序列的实际部署提供了可行路径。
- 开源生态:NVIDIA 同时发布了完整代码、Docker 环境以及 Triton kernel,实现即插即用,预计将在学术与工业界快速传播。
"Gated DeltaNet‑2 展示了在不增加显存开销的情况下,通过细粒度门控提升记忆编辑能力的可能性,值得后续模型设计借鉴。" — 论文第一作者 Ali Hatamizadeh
整体来看,Gated DeltaNet‑2 为线性注意力技术打开了新方向,也为大规模长上下文语言模型提供了更高效的实现路径。未来,结合更大模型规模和多模态输入,可能进一步推动生成式 AI 在高效推理上的突破。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。