Microsoft发布Fara1.5浏览器智能体系列 将网页任务成功率提升至七成以上
•70 阅读•4分钟•前沿
MicrosoftQwen3.5Fara1.5Online-Mind2Web浏览器智能体
•70 阅读•4分钟•前沿
背景与发布
Microsoft Research AI Frontiers实验室正式发布Fara1.5,这是首个面向浏览器的计算使用智能体(Computer‑Use Agent)系列。模型提供4B、9B、27B三种参数规模,全部集成在微软自研的安全沙盒浏览器MagenticLite中,可直接在真实网页上读取截图并输出鼠标、键盘等操作指令。
核心性能
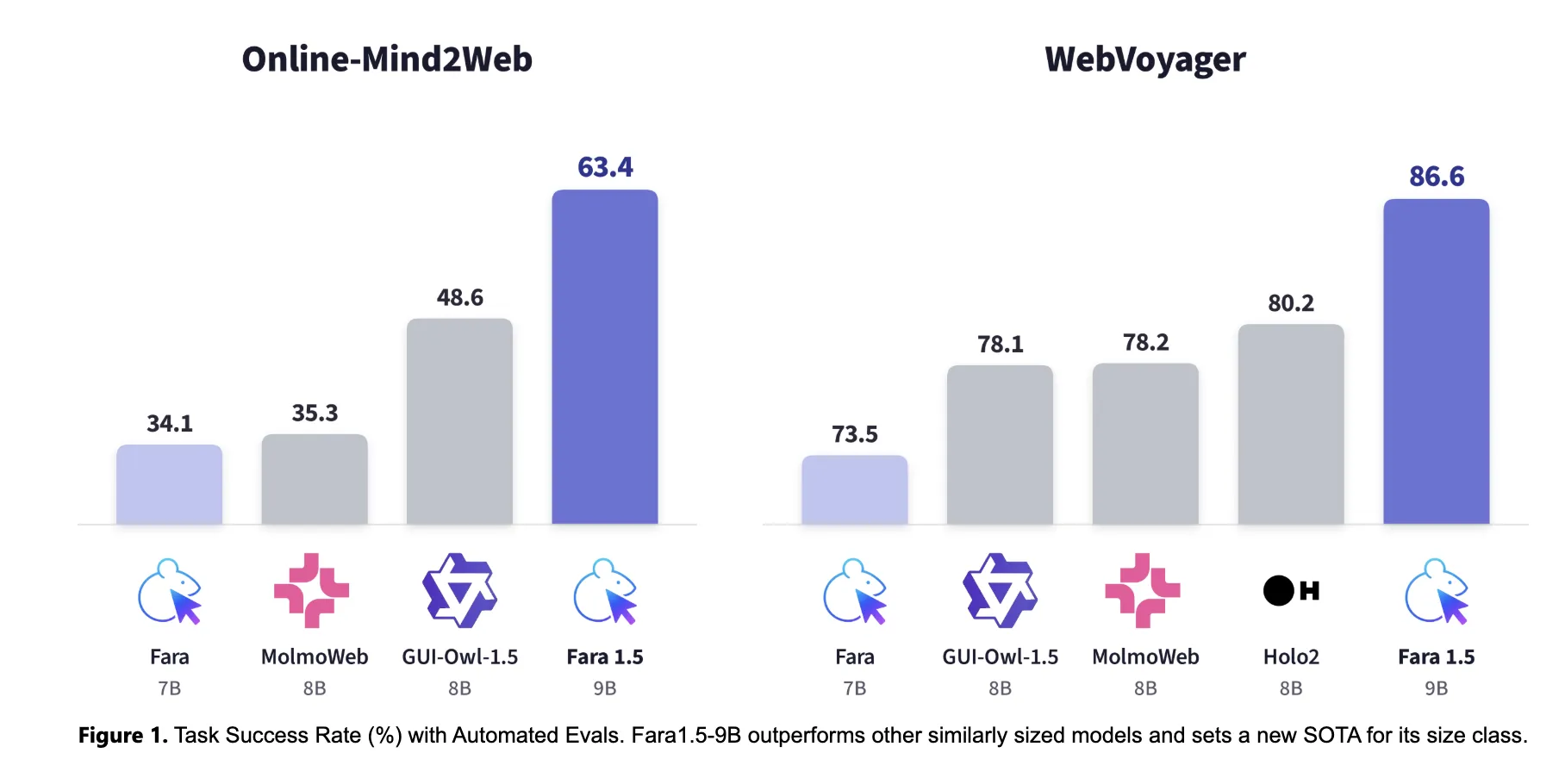
- Online‑Mind2Web基准:Fara1.5‑27B在覆盖136个热门站点、300个任务的评测中取得 72% 成功率;9B版本为63.4%,4B版本为34.1%(前代Fara‑7B)。
- 对比竞争:OpenAI Operator 58.3%,Google Gemini 2.5 Computer Use 57.3%,Yutori Navigator n1 64.7%。
- WebVoyager:27B模型达到88.6%整体得分,9B和4B分别为86.6%和80.8%。
- WebTailBench v1.5(长尾网页任务):9B模型过程成功率64.5%,结果成功率32.3%,相较于GPT‑5.4的79.6%/57.4%仍有提升空间。
训练与合成数据管线(FaraGen1.5)
FaraGen1.5负责生成用于训练的合成轨迹,核心包括三大模块:
- 环境(Envs):
- 开放网络任务直接在真实网站上执行。
- 封闭域任务通过六个自建克隆(邮件、日历、Stream、机器学习、Stay、Scheduler)实现,所有克隆均由GitHub Copilot CLI+人工迭代构建,具备完整前端、API和基于角色的数据库。
- 求解器(Solver):采用OpenAI的GPT‑5.4,工具集与Fara1.5保持一致,在自动化WebJudge上实现83%成功率,显著高于前代求解器的67%。
- 验证器(Verifier):通过LLM生成的评分标准、数据库快照比对以及冗余动作惩罚,过滤出高质量轨迹进入训练。
训练采用约200万条样本的监督微调,数据比例为60%网页轨迹、12.8%合成环境、其余为表单填写、VQA等子任务。损失仅对最近三轮进行计算,以提升长程决策能力。
安全与交互机制
Fara1.5在以下三类情形主动暂停并请求用户确认:
- 需要用户个人信息且未提供时;
- 任务描述模糊或缺失关键细节时;
- 即将执行不可逆操作(如发送邮件、修改设置)时。
所有动作均记录在MagenticLite的审计日志中,沙盒浏览器提供了明确的安全边界,符合微软Responsible AI政策的安全训练规范。
行业意义
Fara1.5展示了大模型在真实网页环境中实现高效、可审计交互的可行路径。其合成数据管线突破了传统只能在开放网页上训练的局限,为企业内部系统、受限业务提供了可复制的训练方案。随着模型规模的提升和安全交互机制的成熟,浏览器智能体有望在客服自动化、企业内部流程编排以及个人助理等场景得到广泛落地。
“从70%到80%以上的任务成功率,标志着大模型已经可以在复杂网页环境中进行可靠的长程规划。” — 微软研究院技术负责人
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。