Cohere发布Command A+ 218B稀疏MoE模型 实现两块H100高效代理工作流
背景与定位
Cohere在近期的模型路线上推出了首个多模态推理模型——Command A+。该模型整合了此前四个独立的Command A系列(基础、推理、视觉、翻译),以统一的Sparse MoE架构面向企业级agentic工作流提供高效算力利用方案。
模型架构
- 参数规模:总参数2180亿,实际激活参数约25亿。
- 专家数:128个专家,每个token激活8个,外加全局共享专家。
- 稀疏路由:采用Top‑k token‑choice router,使用归一化Sigmoid对专家logits进行筛选。
- 注意力层:滑动窗口注意力与旋转位置嵌入交叉,比例3:1;全局注意力层不使用位置嵌入。
- 输入/输出:支持文本、图像、工具调用;输出包括纯文本、推理链路以及工具调用指令。
量化与硬件需求
Cohere提供三种量化选项:
- BF16:需4×B200或8×H100。
- FP8:需2×B200或4×H100。
- W4A4(4位):可在单块B200或2×H100上运行。
W4A4采用NVFP4方案,仅对MoE专家部分进行4位权重‑激活量化,注意力路径保持全精度,并通过Quantization‑Aware Distillation(QAD)弥补精度差距。
性能提升
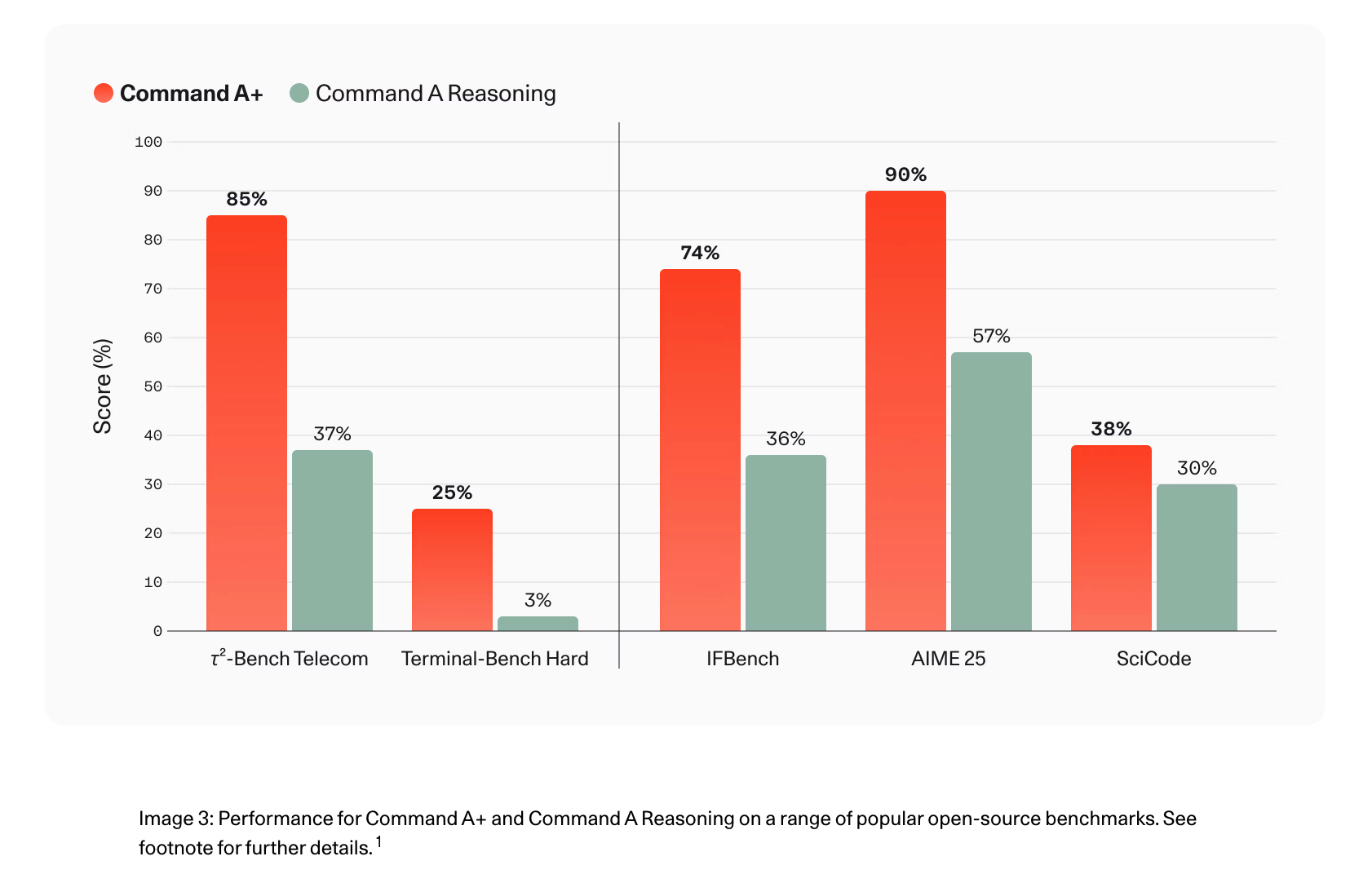
在内部τ²‑Bench Telecom基准上,Command A+的得分从37%提升至85%;在Terminal‑Bench Hard代码任务上,正确率从3%跃升至25%。
- TOPS提升:同等量化条件下,输出吞吐提升最高63%。
- TTFT降低:首 token 延迟降低约17%。
- 稀疏推理加速:专为MoE设计的推测解码再提升1.5‑1.6倍。
多模态与多语言能力
Command A+首次支持多模态推理,在MMMU基准上取得63%(文本)和75.1%(多模态)成绩,接近Vision 版本的65.3%。
语言覆盖从23种扩展至48种,在机器翻译、跨语言推理以及特定语言的分词效率上均有显著提升(阿拉伯语‑20%、韩语‑16%、日语‑18%)。
部署生态
模型兼容vLLM和Transformers库,工具调用通过JSON schema在Transformers chat template 中实现。推理时可在生成文本前插入 <|START_THINKING|> 与 <|END_THINKING|> 标记,输出思考链路。推荐采样参数为 temperature=0.9、top_p=0.95、repetition_penalty=1.04。
结论
Command A+以稀疏MoE技术在保持高质量推理的同时,大幅降低算力门槛,实现了在仅两块H100 GPU上的4位量化部署。这一突破为企业级agentic系统提供了成本友好且多语言多模态兼容的底层模型,预示着大模型在实际业务中的可行性进一步提升。
“Cohere的这一步,不只是模型规模的叠加,更是对稀疏推理生态的系统化输出。”——Cohere官方博客