阿里巴巴推出Qwen3.7-Max 1M上下文推理代理模型
•65 阅读•5分钟•前沿
生成式AIAgentic AIAlibaba1M上下文Qwen3.7-Max
•65 阅读•5分钟•前沿
亮相背景
阿里巴巴的Qwen团队在2026年Alibaba Cloud Summit上宣布,Qwen3.7-Max是其迄今为止最完整的代理模型。相较于此前的Qwen3.6 Max Preview,模型在上下文长度、推理深度以及多步任务执行能力上实现了显著跃升。
关键特性
- 1M Token 上下文窗口:支持单次请求容纳约100万token,可一次性加载中等规模代码库或海量文档。
- 扩展思考模式(Extended‑Thinking):模型先生成内部思考链,再输出最终答案,适用于复杂的代码重构、数学证明等需要多轮推理的场景。
- 纯文本推理旗舰:Qwen3.7‑Max仅支持文本输入/输出,针对长文本推理进行深度优化;对应的多模态版本 Qwen3.7‑Plus‑Preview 仍保留视觉输入能力。
- API 兼容:兼容 OpenAI 与 Anthropic 的接口规范,企业可快速迁移现有流水线。
- 定价待定:参考 Qwen3.6 Max Preview 的 $1.30/每百万 token,预计保持相近水平。
基准成绩与行业对比
| 模型 | Intelligence Index 分数 | 全球排名 |
|---|---|---|
| Qwen3.7‑Max | 56.6 | 第5 |
| Gemini 3.5 Flash | 55.3 | — |
| GPT‑5.5 | 60.2 | — |
| Claude Opus 4.7 | 57.3 | — |
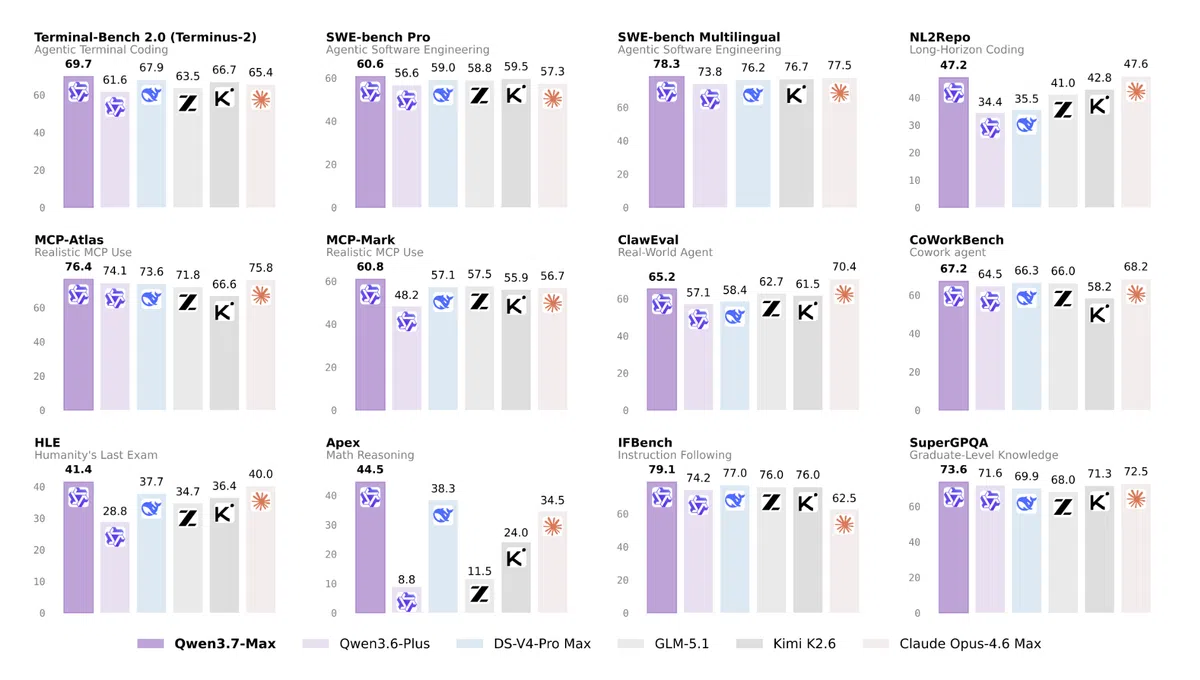
Qwen3.7‑Max 在科学推理、代理能力和代码生成三大维度贡献了近10个百分点的提升,尤其是 CritPt(从 3.7% 提升至 13.4%)和 Humanity’s Last Exam(从 28.9% 提升至 38.1%)表现突出。但在 AA‑Omniscience 上的原始准确率下降 7.6%(从 37.7% 降至 30.1%),同时模型更倾向于“未知”回答,降低了幻觉率。
实际使用场景
- 代码调试与重构:内部测试显示,模型在一次性调用 1,000+ 工具函数、完成数千行代码的迭代优化后,推理速度提升约 10 倍。
- 长链路工作流:凭借 1M token 的上下文容量,可一次性传入完整的任务历史、工具输出与代码状态,实现 35 小时以上的自主执行。
- 企业级文档分析:一次请求即可处理数十万行技术文档或合规材料,适合审计、知识库构建等需求。
已知局限
- 仅限文本:不支持图像或视频输入,需使用 Qwen3.7‑Plus‑Preview 处理多模态任务。
- 事实召回下降:在需要大量事实检索的场景(如百科问答)仍需配合外部检索系统。
- 预览状态:目前仍为 Preview 版本,权重未公开,基准分数和定价可能在正式发布前调整。
快速上手指南
1. 前往 chat.qwen.ai 注册免费账号。
2. 在模型下拉框中选择 **Qwen3.7‑Max**(或 **Qwen3.7‑Max‑Preview**)。
3. 开启 **Thinking Mode** 以查看模型的思考链。
4. 若需 API 调用,使用以下示例(兼容 OpenAI 规格):
```python
from openai import OpenAI
client = OpenAI(api_key="YOUR_DASHSCOPE_API_KEY",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1")
resp = client.chat.completions.create(
model="qwen3.7-max",
messages=[{"role": "user", "content": "解释链式思考机制。"}],
extra_body={"enable_thinking": True}
)
print(resp.choices[0].message.content)
提示:长上下文请求请务必在请求体中压缩无关信息,以控制成本。
展望
Qwen3.7-Max 的发布表明阿里巴巴正加速布局“长链路智能代理”赛道。随着上下文窗口进一步扩大、思考模式成熟,未来模型将在企业级自动化、代码治理以及深度科研辅助等领域发挥更大价值。行业观察人士预计,后续的正式版将进一步开放权重或提供混合云部署选项,以争夺企业级大模型市场份额。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。