字节跳动发布Lance,首个统一图像视频理解与生成的3B模型
•54 阅读•5分钟•前沿
文生视频字节跳动Lance统一多模态
•54 阅读•5分钟•前沿
背景与意义
随着生成式AI快速发展,图像与视频任务往往采用不同的模型体系,导致研发成本和推理资源大幅提升。字节跳动智能创作实验室在最新论文 (arXiv:2605.18678) 中提出 Lance,通过单一模型实现图像、视频的理解、生成以及编辑,标志着多模态统一模型进入实用化阶段。
模型概览
- 规模:3B 激活参数,基于 Qwen2.5‑VL 3B 初始化。
- 任务覆盖:
- 理解:图像/视频字幕、视觉问答、OCR、视觉定位与推理。
- 生成:文本到图像、文本到视频、图像到视频、主题驱动生成。
- 编辑:图像编辑、视频编辑,支持跨模态多轮一致性。
- 架构核心:双流 Mixture‑of‑Experts(理解专家 LLMUND、生成专家 LLMGEN)共享统一的交叉模态序列。
关键技术创新
- 统一上下文建模:所有输入(文本、图像、视频)被转化为同一交错序列;文本 Token 来自 Qwen2.5‑VL 嵌入层,语义视觉 Token 来自 ViT 编码器,生成视觉 Token 来自 3D Causal VAE。
- Modality‑Aware Rotary Positional Encoding (MaPE):为不同模态的 Token 添加固定时间偏移,防止位置冲突,实现跨任务对齐。实验表明,去除 MaPE 会导致 GenEval、GEdit‑Bench、VBench 等指标整体下降 0.3~1.0 分。
- 双流专家解耦:理解专家负责离散语义 Token,生成专家负责连续潜在 Token,二者在同一上下文中并行计算,既共享信息又避免参数竞争。
训练流程与资源
| 阶段 | 数据规模 | 关键任务 | 备注 |
|---|---|---|---|
| PT(预训练) | 1B 图文 + 140M 视频文对 | 基础跨模态对齐与生成 | 冻结 VAE 与 ViT,仅训练主干 |
| CT(持续训练) | 300B Token | 编辑、主题驱动生成、跨模态理解 | 逐步提升难度比例 |
| SFT(指令微调) | 72B Token | 指令遵循、编辑精度、身份一致性 | |
| RL(强化学习) | — | 使用 PaddleOCR 作为奖励模型提升文本渲染与对齐 | 资源上限 128 GPU |
性能评测
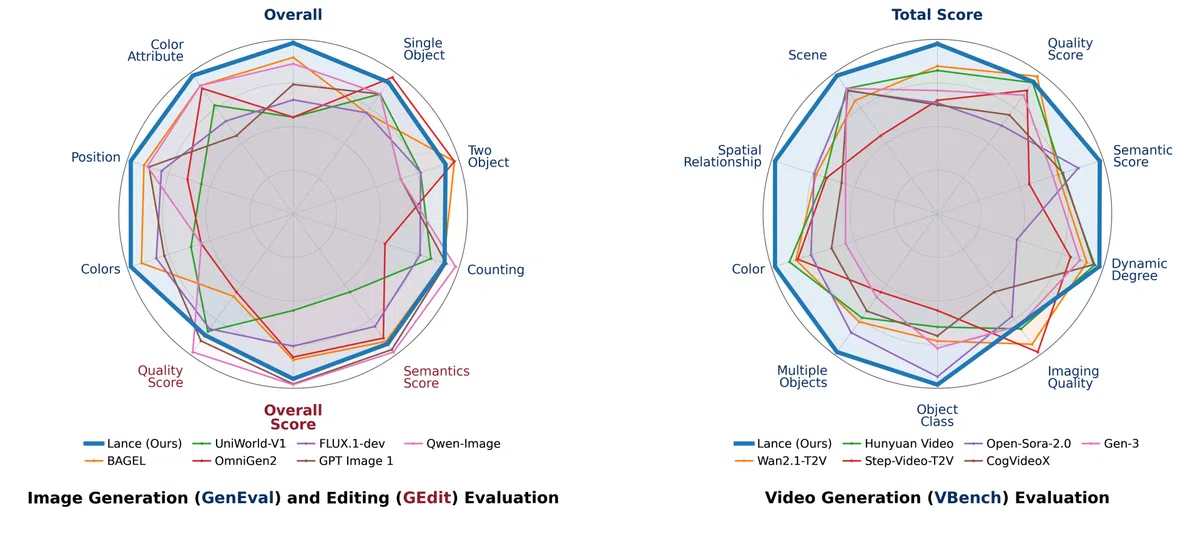
- GenEval(图像生成):0.90,持平 TUNA,显著优于 Janus‑Pro‑7B(0.80)和 Show‑o2(0.76)。
- VBench(视频生成):总分 85.11,领先所有统一模型,次席 TUNA 为 84.06。
- GEdit‑Bench(图像编辑):7.30,统一模型最高,尤其在背景替换、运动变化等子项全线领先。
- MVBench(视频理解):62.0,统一模型最高,远超同等参数的 Show‑o2(55.7)。
这些结果表明,Lance 在保持 3B 参数规模的同时,兼顾了理解、生成与编辑三大能力,实现了 参数效率 与 功能完整性 的双重突破。
开源使用指南
- 环境要求:CUDA 12.4+,GPU 显存 ≥ 40 GB,Python ≥ 3.10。
- 代码获取:
git clone https://github.com/bytedance/Lance && cd Lance - 依赖安装:
conda create -n lance-env python=3.10 -y && conda activate lance-env && pip install -r requirements.txt - 模型下载:使用 HuggingFace CLI 下载
bytedance-research/Lance权重至downloads/目录。 - 推理调用:通过
inference_lance.sh指定任务(t2i、t2v、image_edit、video_edit 等)即可运行;亦可启动lance_gradio_t2v_v2t.py进入可视化界面。
完整的安装与运行步骤详见官方 README,社区已提供多套示例配置,便于快速上手。
业界影响
Lance 的发布展示了 单模型统一多模态 的可行路径,为内容创作、广告生成、媒体后期等场景提供了低成本、高一致性的技术底座。与此同时,开源 Apache 2.0 许可证降低了企业与研究机构的准入门槛,预计将在国内外的生成式AI生态中掀起新一轮模型复用与创新浪潮。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。