NVIDIA推出Nemotron‑Labs‑Diffusion 三模解码模型 首次实现6倍并行吞吐
•35 阅读•5分钟•前沿
NVIDIALoRADiffusionNemotron-Labs-Diffusion自回归
•35 阅读•5分钟•前沿
模型概览
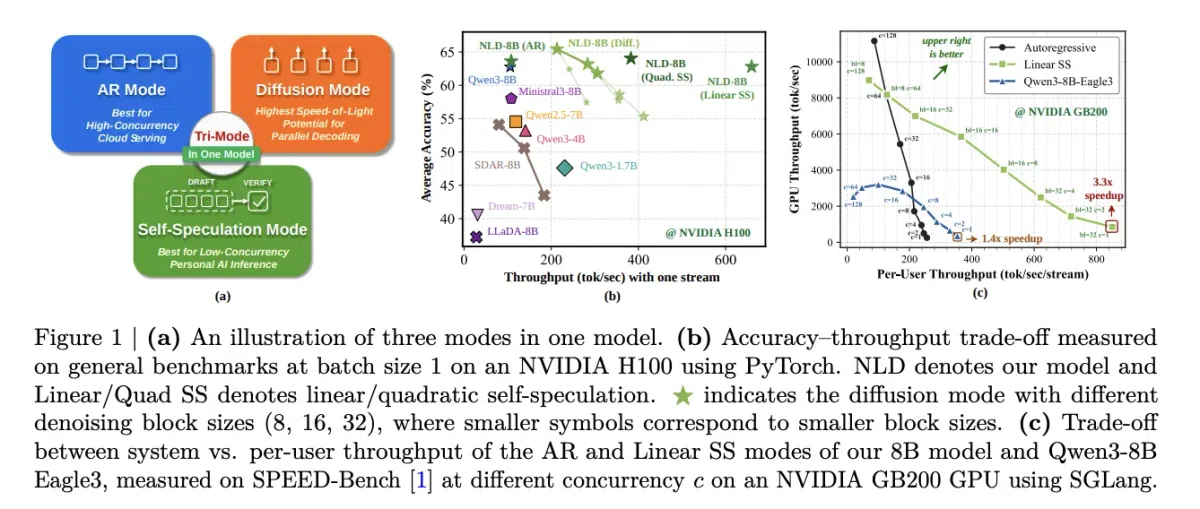
NVIDIA 本次开源的 Nemotron‑Labs‑Diffusion 系列是一套 三模态(Tri‑Mode)语言模型,在同一权重下支持三种解码路径:
- 自回归(AR)模式:传统左到右生成,适配现有高并发云服务。
- 扩散(Diffusion)模式:将序列划分为固定长度块,块内双向注意力并行去噪,显著提升 Tokens‑per‑Forward(TPF)。
- 自我推理(Self‑Speculation)模式:先用扩散路径草稿 k 个候选 token,再用 AR 路径验证最长匹配前缀,无需额外草稿模型或额外 head。
模型提供 3B、8B、14B 三个规模,且每个规模都有 Base、Instruct、VLM(视觉语言) 三种变体,全部基于 NVIDIA 的 Ministral3 预训练权重,使用 Megatron‑Bridge 统一训练与推理管线。
训练细节
- 联合目标:(L(θ)=L_{AR}(θ)+α·L_{diff}(θ)),α 固定为 0.3,实验表明该比例在 0.1‑0.5 范围内对两种模式的精度均无负面影响。
- 两阶段训练:先以自回归目标训练 1 万亿 token,构建强左‑右语言先验;随后加入扩散目标再训练 3000 亿 token,整体提升约 16.05% 的平均准确率。
- LoRA 增强:在自我推理的扩散草稿路径上加入 LoRA(rank 128,α=512),仅占模型 0.4% 参数,却在 3B/8B/14B 三个规模上分别提升 14.4%、32.5% 与 27.6% 的 TPF,精度基本保持不变。
性能与基准
| 模型 | 模式 | 平均准确率 | TPF 提升 |
|---|---|---|---|
| NLD‑8B | AR | 63.61% | 1× (基准) |
| NLD‑8B | Diffusion | 63.18% | 2.57× |
| NLD‑8B + LoRA | Self‑Speculation | 62.81% | 5.99× |
| NLD‑14B + LoRA | Self‑Speculation | 66.36% | 5.96× |
在 SPEED‑Bench(SGLang + NVIDIA GB200)上,线性自我推理模式相较 Qwen3‑8B 提供 4× 吞吐提升,单用户场景下比同尺寸 AR 模式快 3.3×。理论上限(Speed‑of‑Light)可达 7.6×,当前实现约为 3×,仍有显著提升空间。
使用指南
from transformers import AutoModel, AutoTokenizer
repo = "nvidia/Nemotron-Labs-Diffusion-8B"
tokenizer = AutoTokenizer.from_pretrained(repo, trust_remote_code=True)
model = AutoModel.from_pretrained(repo, trust_remote_code=True).cuda().bfloat16()
# 选择模式
out_ids, nfe = model.ar_generate(prompt_ids, max_new_tokens=512) # AR
out_ids, nfe = model.generate(prompt_ids, max_new_tokens=512, # Diffusion
block_length=32, threshold=0.9)
out_ids, nfe = model.linear_spec_generate(prompt_ids, # Self‑Speculation
max_new_tokens=512, block_length=32)
- 部署:支持 vLLM 与 SGLang,两者均提供 OpenAI‑compatible 接口,便于在现有 API 网关上直接替换。
- 场景匹配:
- 高并发云推理 → AR 模式,利用批处理最大化 GPU 利用率。
- 单用户或边缘设备 → Self‑Speculation + LoRA,显著降低每次前向计算次数。
- 对吞吐与精度有弹性需求 → Diffusion 模式,可调阈值在速度与准确率间自由权衡。
行业意义
Nemotron‑Labs‑Diffusion 打破了“解码模式即模型架构” 的传统限制,展示了 同一权重多模解码 的可行性。对于云服务提供商,它意味着在不增大模型规模的前提下即可实现数倍的吞吐提升;对于边缘部署,它提供了在算力受限环境下仍能保持高质量生成的路径。随着 LoRA 与更高效采样器的进一步研发,预计该框架的实际 TPF 将逼近理论上限,为生成式 AI 的 算力‑效率 变革奠定基础。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。