MemPrivacy框架实现本地可逆伪匿名,边缘云记忆保护隐私且不损效用
背景
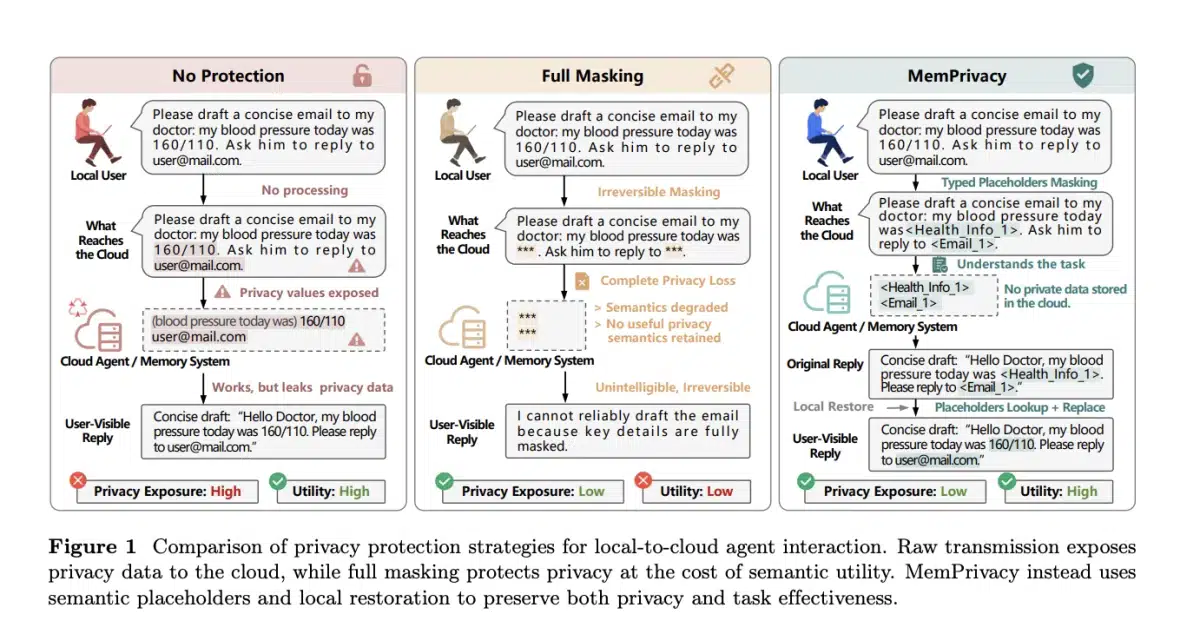
随着大语言模型(LLM)驱动的智能体从实验走向产品,云端记忆成为提升个性化服务的关键。但用户对话中常混杂健康、财务、密码等高度敏感信息,一旦原始文本直接上云,便会在日志、向量库等后端存储中长期留存,形成严重隐私风险。已有研究表明,多轮记忆攻击成功率可达69%,泄漏攻击甚至高达75%。传统的遮蔽(如用"***")虽能阻断泄露,却会破坏语义,导致模型生成质量大幅下降。
MemPrivacy核心设计
MemPrivacy提出本地可逆伪匿名的三阶段流水线:
- 上行脱敏(Uplink Desensitization):在设备端运行轻量模型,检测并按类型将隐私片段替换为结构化占位符(如"<EMAIL>"、"<HEALTH>"),并在本地安全数据库中保存原文‑占位符映射。
- 云端处理(Cloud Processing):云端模型收到的仅是占位符文本,保留了信息的类型与上下文结构,可正常完成记忆构建、检索与推理。
- 下行恢复(Downlink Restoration):云端返回的响应若含占位符,设备端快速查表替换为真实值,用户看到的仍是完整、个性化的答案。
四级隐私分类
MemPrivacy定义了PL1‑PL4四层隐私等级,以帮助用户灵活配置保护范围:
- PL1:偏好、习惯等非身份信息(默认不保护)。
- PL2:可识别的个人信息,如姓名、邮箱、手机号。
- PL3:高度敏感信息,包括健康记录、金融账户、精准位置信息等。
- PL4:直接可被利用的凭证,如密码、OTP、API Key 等。用户可自行设定仅屏蔽PL3‑PL4或全覆盖PL2‑PL4,实现隐私‑效用的细粒度平衡。
数据集与模型训练
团队构建了MemPrivacy‑Bench,覆盖200个合成用户画像、155k+隐私实例,兼顾中英双语对话,涵盖7大场景与23个细分类。标注流程先由Gemini‑3.1‑Pro 与 GPT‑5.2 双模型生成,再经六名人工审校,最终标注准确率达98.08%。模型基于Qwen‑3 系列,在0.6B、1.7B、4B 参数规模上分别进行监督微调(SFT)并使用**组相对策略优化(GRPO)**进行强化学习,奖励信号为F1分数。
实验结果
在MemPrivacy‑Bench测试集上,最佳模型 MemPrivacy‑4B‑RL 达到85.97% F1,领先 Gemini‑3.1‑Pro(78.41%)近8个百分点;在跨域PersonaMem‑v2基准上亦取得94.48% F1,超过DeepSeek‑V3.2‑Think(92.18%)。相比之下,OpenAI公开的Privacy‑Filter 仅为35.50% F1。 在实际记忆系统(LangMem、Mem0、Memobase)中启用PL2‑PL4保护时,整体准确率下降控制在0.73%‑1.60% 之间;而传统不可逆遮蔽导致的准确率下降最高可达41.87%。这表明MemPrivacy在保持记忆效用的同时,实现了显著的隐私防护。
业界意义与展望
MemPrivacy的可逆占位符机制为边缘‑云协同提供了一条实用且高效的隐私路径,特别适配资源受限的移动设备与IoT 场景。模型推理时延约2秒,远低于同等精度的全加密方案,具备商用落地的潜力。未来可进一步融合同态加密或差分隐私,提升对极端安全需求的保障;同时,随着用户对数据主权认知提升,类似的分层隐私框架有望成为行业标准。
“隐私不应以牺牲用户体验为代价”,MemPrivacy的实验结果正是对此的有力证明。