Nous Research推出Lighthouse注意力实现长上下文预训练加速1.7倍
•27 阅读•4分钟•前沿
长上下文Nous ResearchFlashAttentionLighthouse Attention
•27 阅读•4分钟•前沿
背景与挑战
Transformer 的标度瓶颈主要来源于标量点积注意力的 (\Theta(N^2)) 计算和内存开销。即便 FlashAttention 通过 IO‑aware 切分降低了显存占用,算力成本仍随序列长度呈二次增长,导致长上下文预训练成本高企。现有稀疏注意力方法(如 NSA、HISA)普遍只压缩键值,而保留查询全分辨率,且将选择逻辑硬编码进自定义 kernel,难以复用 GPU 的高效密集算子。
Lighthouse注意力的核心创新
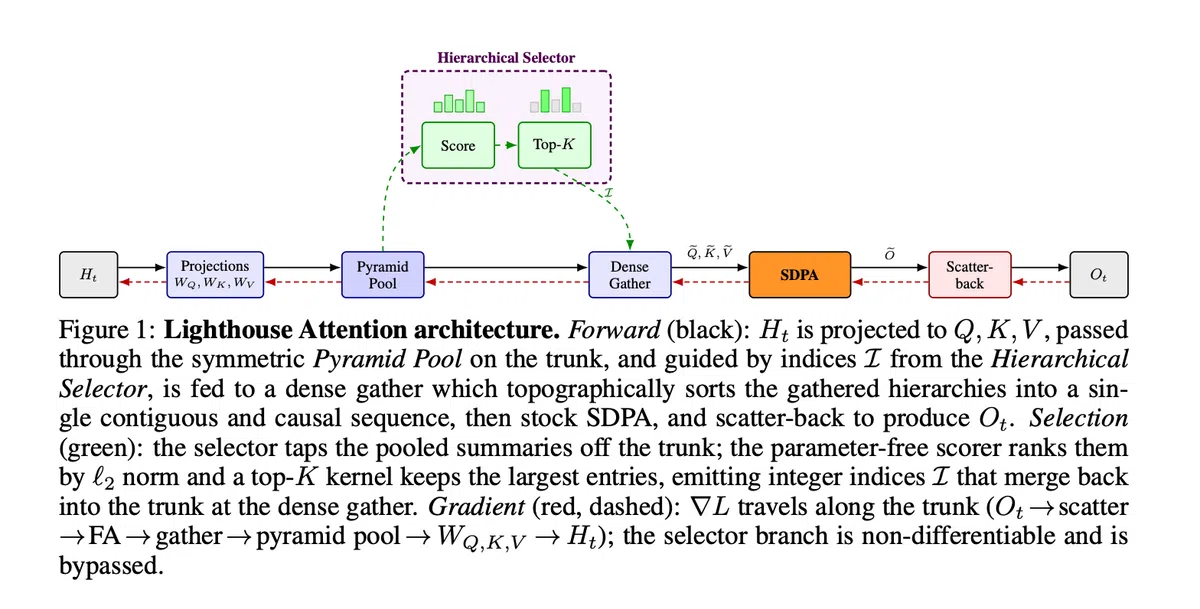
Lighthouse 采用四阶段流水线:
- 对称金字塔池化——对 Q、K、V 同步使用平均池化构建 (L) 层金字塔,池化因子为 (p)。每层 token 数为 (N/p^\ell),整体成本 (\Theta(N))。
- 参数无关评分与分块 Top‑K——利用每头 (\ell_2) 范数分别为查询和键生成标量分数,跨层统一做分块位元拓扑排序的 Top‑K 选择,保证每个粗层都有完整覆盖。
- 密集子序列聚合——将选中的 (k) 条目在所有层合并为连续子序列 (S),随后使用原生 FlashAttention 完成注意力计算。
- 散回与因果修正——通过整数原子散回把子序列的输出映射回原始位置,确保每个基 token 都得到梯度。
对称池化将注意力调用从 (O(N\cdot S\cdot d)) 降至 (O(S^2\cdot d)),在长上下文(如 512K)下可把前向计算提速 21 倍,前向+反向提速 17.3 倍。
实验结果与性能提升
- 模型:530M 参数 Llama‑3 风格解码器,98,304 token 上下文。
- 硬件:单块 NVIDIA B200,bfloat16。
- 速度:在 512K 长度下前向 21×、前向+反向 17.3× 加速。整体训练时钟提升 1.40‑1.69×,相当于在相同 token 预算下缩短约 10 小时。
- 训练质量:两阶段恢复后最终损失 0.6980‑0.7102,均低于密集基线 0.7237。
- 检索评估:在 Needle‑in‑a‑Haystack 任务中,Lighthouse 配置 (k=2048, dilated scorer) 达到 0.76 的平均检索率,超过基线 0.72。
两阶段训练与可恢复性
- 阶段‑1 – 大部分步数使用 Lighthouse 进行稀疏训练,实现约 2× 吞吐提升。
- 阶段‑2 – 在同一优化器状态下切换回密集 FlashAttention,损失会短暂上升 1.12‑1.57 nats,随后在 1,000‑1,500 步内恢复并最终低于基线。此实验验证了稀疏预训练不会破坏模型在全注意力推理时的表现。
规模化与局限性
- 上下文并行:在 1M token 规模下,Lighthouse 通过在每个 GPU 本地完成金字塔池化和 Top‑K 选择,随后使用标准环形注意力进行密集子序列计算,几乎不产生跨卡通信,保持 10% 左右的环形开销。
- 推理限制:Lighthouse 为训练专用方法,查询在推理阶段逐个出现,违背对称池化的假设,故需在训练结束后恢复为全密集注意力。
- k 与 N 的关系:当前实验固定 k 在数千级别,未探讨 k 随 N 增长的情形,仍是后续研究方向。
结语
Lighthouse Attention 通过对称的 Q/K/V 池化与外部选择机制,在保持软最大注意力召回能力的同时,实现了接近线性复杂度的训练成本,是长上下文大模型预训练的实用突破。未来可期待在更大模型、跨模态以及自适应 k 选择上的进一步优化。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。