Zyphra发布ZAYA1-8B-Diffusion-Preview 实现首个MoE扩散模型 最高7.7倍推理加速
背景概述
Zyphra是总部位于旧金山的AI实验室,先前推出的ZAYA1系列模型采用Mixture-of-Experts(MoE)架构,已在大规模语言建模中展现出优秀的规模效应。近期团队发布的ZAYA1-8B-Diffusion-Preview,标志着首次将自回归MoE模型成功转换为离散扩散模型,并在AMD MI300x/MI355x GPU上实现显著的推理加速。
为何自回归解码成为瓶颈
传统的大语言模型采用自回归方式逐 token 生成,每一步都需要从显存中读取 KV‑cache 并完成注意力计算。由于每个请求的历史不同,缓存无法共享,导致 GPU 大部分时间在等待内存带宽,呈现memory‑bandwidth bound。而现代 GPU 的 FLOPs 增长速度远快于内存带宽,导致算力利用率下降。
扩散模型的计算优势
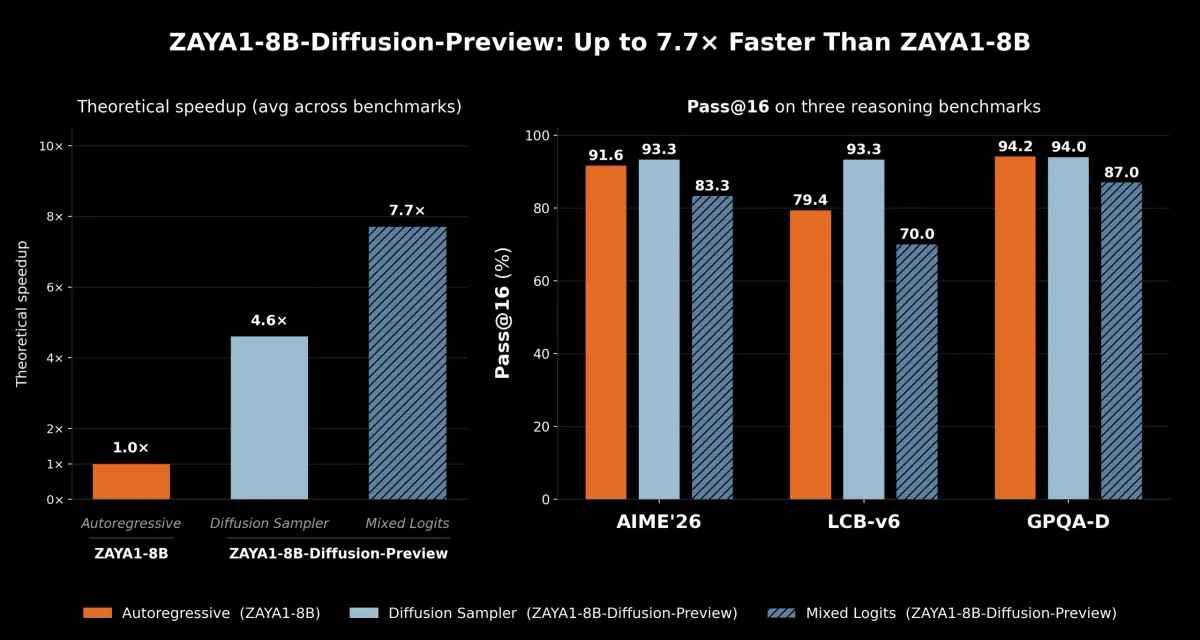
扩散语言模型一次生成 N 条 token(ZAYA1‑Diffusion 设为 16),所有 token 共享同一 KV‑cache,计算过程从内存带宽受限转为算力受限(compute‑bound),显著提升 GPU 利用率。ZAYA1-8B-Diffusion-Preview 采用单步从 mask 到 token 的转换,在一次前向传播中完成 16 条 token 的草稿生成。
转换流程与训练细节
- 基模型:使用 ZAYA1-8B‑base(自回归 MoE)检查点。
- 扩散中期训练:在 TiDAR 配方下,以 32k 上下文长度继续训练 6000 亿 token。
- 上下文扩展:再以 128k 长度训练 5000 亿 token,提升长文本处理能力。
- 扩散 SFT:最后进行扩散监督微调,累计约 1.1 万亿 token。
该路径避免了从零开始训练扩散模型的高难度和高成本,因为训练阶段本身已是算力受限,瓶颈只在推理时出现。
推理采样器与加速效果
- 无损扩散采样器:采用标准的 speculative decoding 接受准则 `min(1, p(x)/q(x))`,在不牺牲评估指标的前提下实现约 4.6 倍加速。
- Logit‑mixing 采样器:将扩散模型与自回归模型的 logits 进行混合,提升接受率,最高可达 7.7 倍加速,伴随轻微质量损失。
两种采样器均在同一模型内部完成草稿与验证的前向传播,无需额外的草稿模型,进一步削减了传统 speculative decoding(如 EAGLE、dFlash)中的额外开销。
架构亮点
- CCA 注意力:Zyphra 为 ZAYA1 系列定制的 CCA(Cache‑Centric Attention)显著降低前缀填充 FLOPs,配合扩散的块级生成,实现更高并行度。
- CCGQA 设计:查询头与键头比例 4:1,压缩率 2×,避免了 Multi‑Head Latent Attention 的高算术强度。
- 硬件协同:在 AMD MI300x(bf16)上每次前向可处理约 3 个块,在 MI355x 上提升至约 5 个块,充分利用了 AMD GPU 的大容量显存。
实际意义
- 服务推理:在内存带宽受限的批量服务场景下,GPU 利用率提升,使得同等硬件成本下可支持更高 QPS。
- RL 训练:更快的生成降低了 on‑policy rollout 的计算开支,为大规模强化学习和指令微调提供了更经济的算力路径。
- 生态示范:首次在 AMD GPU 上完成扩散语言模型训练,展示了非 NVIDIA 硬件在前沿生成模型研发中的可行性。
结论
Zyphra 的 ZAYA1-8B-Diffusion-Preview 通过将自回归 MoE 模型转化为离散扩散模型,成功实现了 4.6‑7.7 倍的推理加速,并在保持或略有提升评估表现的同时,提供了更高效的算力利用方案。这一突破为大模型服务化、强化学习和跨硬件生态的布局提供了新的技术参考。