Poetiq元系统自动打造模型无关Harness,全面提升LLM在LiveCodeBench Pro编码成绩
•37 阅读•4分钟•前沿
GeminiKimiPoetiqGPT 5.5LiveCodeBench Pro
•37 阅读•4分钟•前沿
背景概述
LiveCodeBench Pro(LCB Pro)是面向竞争编程题目的高强度编码基准,强调答案的正确性、运行时长与内存限制,并持续更新题库以防止数据污染。相较于SWEBench等侧重工具使用的评测,LCB Pro更直接检验模型的程序推理与高效实现能力,因而成为衡量生成式AI商业化编码水平的关键指标。
Poetiq元系统的核心思路
Poetiq的Meta‑System被设计为一种自我递归改进的任务编排引擎。它仅使用公开的API(本例中选取Gemini 3.1 Pro)作为底层模型,自动完成以下三步:
- 任务拆解:依据LCB Pro的三维评估(准确性、运行时、内存)生成多轮提问链,确保每一步都围绕约束条件展开。
- 提示优化:通过强化学习与历史交互数据迭代提示模板,使模型在每一次调用中都能输出更符合约束的代码片段。
- 答案聚合:将多次调用的中间结果进行结构化合并、错误修正与性能评估,输出最终可直接提交的代码。
整个过程无需对底层模型进行微调,也不依赖模型内部激活信息,完全基于推理层面的调度与提示工程实现。
实验结果概览
Poetiq在Gemini 3.1 Pro上完成Harness的构建后,将同一套Harness原封不动地迁移至其他七个模型,包括:
- GPT 5.5 High
- Kimi K2.6
- Gemini 3.0 Flash
- Claude Opus 4.7
- Nemotron 3 Super 120B
- 以及若干开源小模型
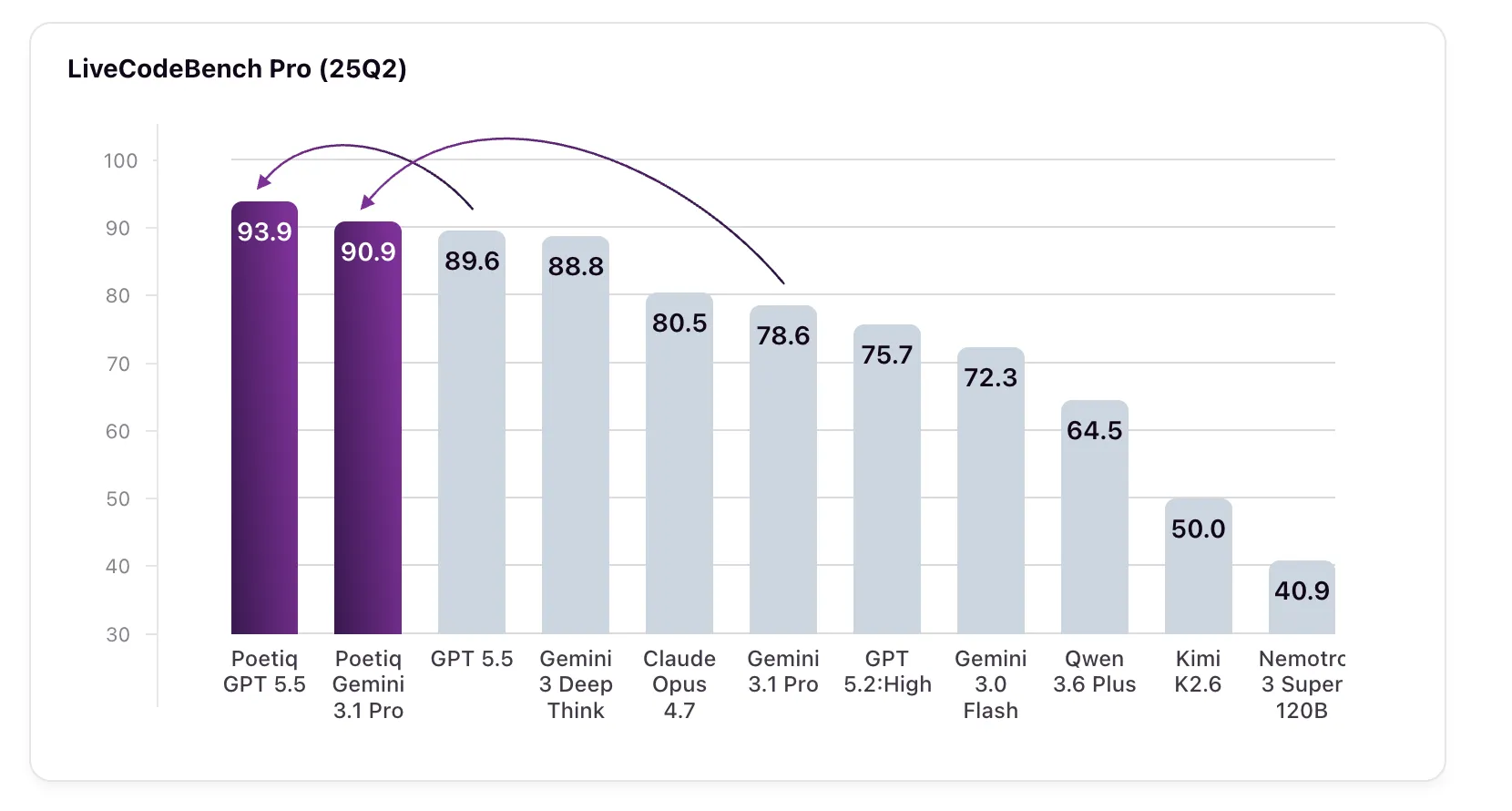
在LCB Pro 25Q2排行榜上,各模型的关键提升如下:
- GPT 5.5 High:93.9% → 89.6%(提升4.3个百分点)
- Gemini 3.1 Pro:90.9% → 78.6%(提升12.3个百分点),超越Google内部的Gemini 3 Deep Think(88.8%)
- Kimi K2.6:79.9% → 50.0%(提升约30个百分点)
- Gemini 3.0 Flash:82.3% → 72.3%(提升10个百分点),在规模更大的模型上实现逆超越
- Nemotron 3 Super 120B:提升12.8%
在Hard难度区间,Gemini 3.1 Pro的得分从7.7%跃升至58.3%,显示出Harness对高难度问题的显著增益。
行业意义与后续展望
- 模型无关的性能提升路径:传统上提升LLM编码能力依赖微调或专属插件,Poetiq的做法表明通过推理层面的自动编排即可实现跨模型的统一增益。
- 成本与效率双赢:小模型(如Gemini 3.0 Flash)在加入Harness后即可超越更大、更贵的模型,降低企业部署高效编码助手的算力成本。
- 递归自我改进的可复制性:Meta‑System的自我迭代机制为其他任务(如数学推理、检索)提供了通用框架,未来有望形成“一站式任务编排平台”。
Poetiq计划进一步开放Meta‑System的API,并将在下一轮基准(LCB Pro 25Q3)中验证其对新题目的适应性。若该技术能够在实际开发环境中保持同等增益,将对AI编码助手的商业化落地产生深远影响。
“我们希望通过自动化的任务编排,让每一代语言模型都能发挥出超出其原始能力的潜力。”——Poetiq技术团队
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。