Nous Research推出Token Superposition Training 将LLM预训练加速最高2.5倍
背景与挑战
大规模语言模型(LLM)的预训练成本居高不下,算力与时间成为制约模型规模扩展的主要瓶颈。传统提升效率的手段多依赖模型并行、混合专家(MoE)或改进分词器,但往往伴随架构修改或实现复杂度提升。Nous Research针对这一痛点,提出无需改动模型或训练流水线的Token Superposition Training(TST),在等算力(FLOPs)条件下实现显著的时钟时间加速。
方法概述
TST 将标准的逐词预测训练拆分为两段:
-
Phase 1 – Superposition
- 将输入序列按长度 L 划分为不重叠的 s 个连续 token 包(bag)。
- 在嵌入层将每个 bag 的 s 个 token 向量取平均,得到一个 “s‑token”。
- Transformer 只需处理长度为 L/s 的序列,算力保持不变,因为输入长度被放大了 s 倍。
- 预测目标从单个下一个 token 变为下一个 s token 包,使用多热交叉熵(MCE) loss:对 s 个目标取平均即可实现,无需额外 head。
-
Phase 2 – Recovery
- 在完成总步数的比例 r(经验值 0.2‑0.4)后,恢复标准的逐词预测。
- 直接从 Phase 1 的 checkpoint 继续训练,所有 TST 代码被移除,模型结构保持不变。
- 过渡阶段会出现约 1‑2 nats 的短暂 loss 峰值,随后快速恢复并最终跑赢基线。
关键超参数包括 bag 大小 s(3‑16)和超参数比例 r,不同模型规模对应不同最优组合。
实验验证
TST 在四个规模上完成验证:
- 270M 与 600M dense(基于 Llama3‑8B tokenizer)
- 3B dense(SmolLM3 形态)
- 10B‑A1B MoE(Qwen3 系列)
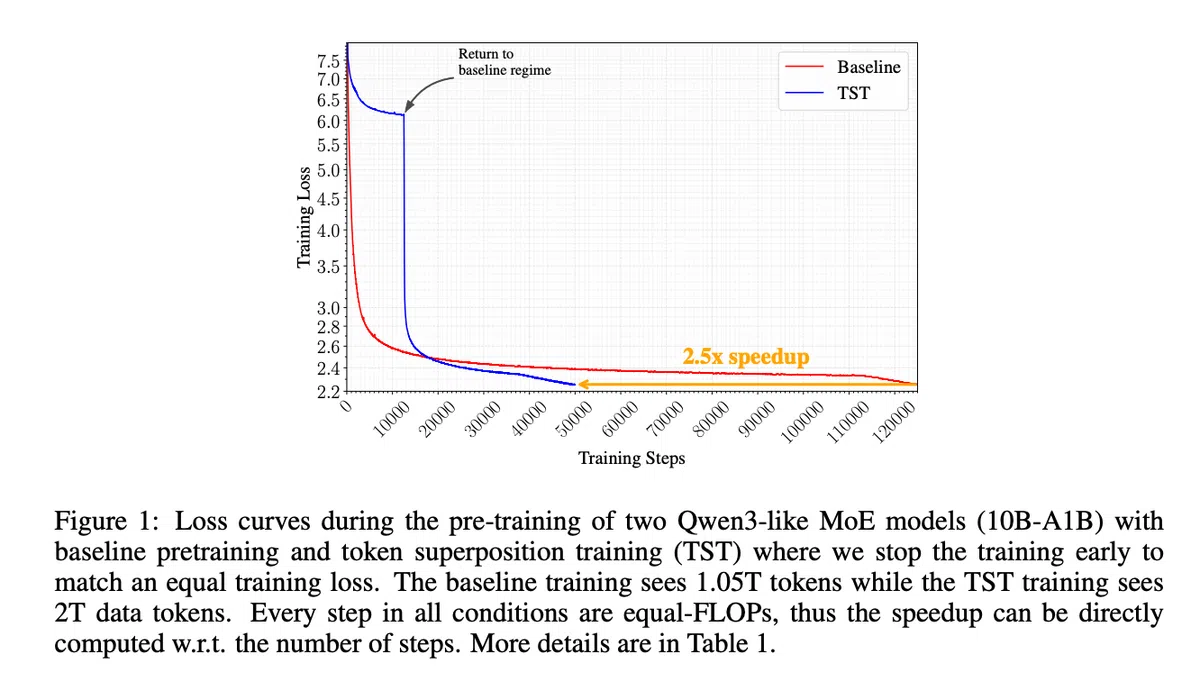
在 10B‑A1B MoE 场景下,使用 s = 16、r≈0.25,TST 仅耗费 4,768 B200‑GPU‑hour,基线则需要 12,311 小时,实现约 2.5× 加速。模型最终 loss 为 2.236,低于基线的 2.252;在四项下游评测(HellaSwag、ARC‑Easy、ARC‑Challenge、MMLU)均取得领先。
等算力、等 loss 条件下,TST 均优于基线;但在等数据量(token)比较时,基线略胜一筹,表明 TST 通过增加 Phase 1 的数据消耗换取算力效率。
实践意义
- 计算受限场景:当算力是主要瓶颈且数据充足时,TST 可显著缩短训练周期,降低成本。
- 无侵入式部署:无需改动模型架构、分词器或优化器,只在训练脚本层面加入两行代码即可实现。
- 兼容性强:适用于 dense 与 MoE 两类模型,且在公开的 PyTorch/FSDP 环境下已验证。
需要注意的是,TST 在 Phase 1 期间会消耗 s 倍的原始 token,因此在数据受限或希望在等 token 条件下比较时应慎用。
结论与展望
Token Superposition Training 为 LLM 预训练提供了一条高效、低侵入的加速路径。未来工作可探索更细粒度的 bag 划分策略、与多 token 预测(MTP)等其他高吞吐技术的组合,以及在更大规模模型(≥100B)上的实证。
参考链接
- arXiv 论文: https://arxiv.org/pdf/2605.06546
- Nous Research 项目主页: https://nousresearch.com/token-superposition