状态空间模型崛起:线性时序架构挑战Transformer主流
•22 阅读•3分钟•前沿
LLMTransformerState Space Models线性时序模型
Jesus Rodriguez••22 阅读•3分钟•前沿
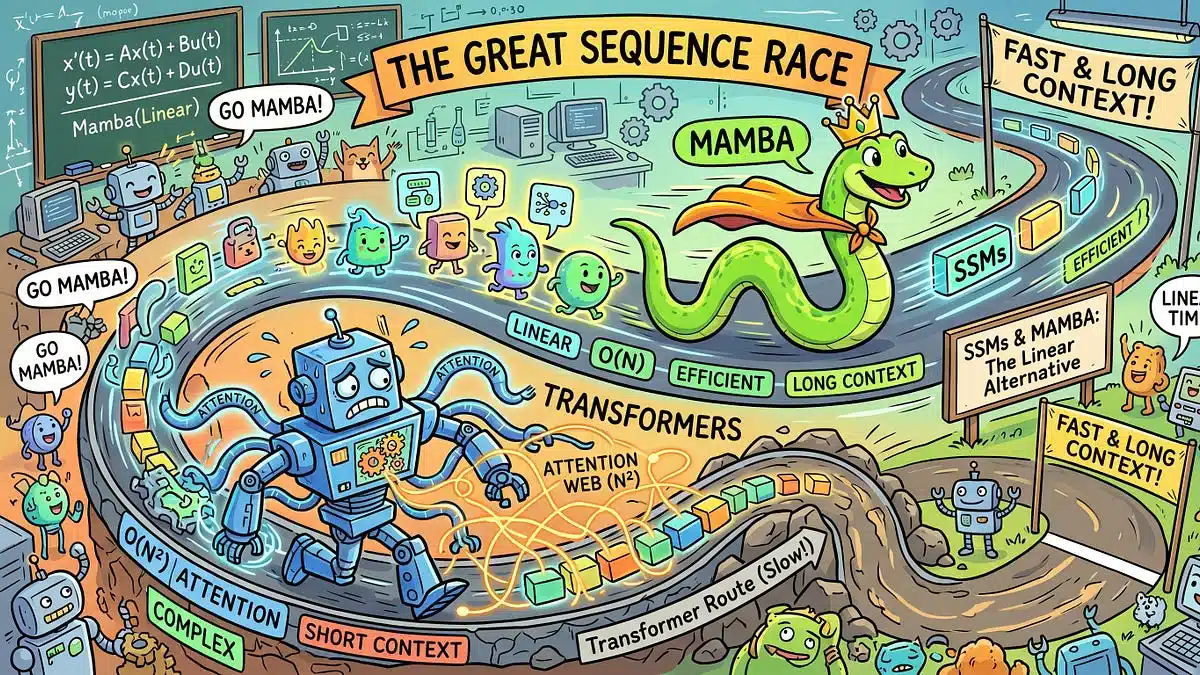
背景与挑战
过去八年,Transformer凭借自注意力机制主导自然语言处理和生成式AI。其核心优势在于并行计算和强大的上下文捕获能力,但代价是
- 时间复杂度 (O(n^2)) 随序列长度呈二次增长
- 推理阶段需要庞大的 KV‑cache,常常占用数十 GB 显存
当模型的上下文窗口突破百万 token,或在 70B 参数模型上进行实时推理时,这些瓶颈已不再是学术话题,而是直接限制产品化的关键障碍。
状态空间模型的优势
状态空间模型(State Space Models, SSM)提供了全新的计算契约:
- 线性时间复杂度:推理成本随序列长度呈线性增长,极大缓解长序列处理压力。
- 常数内存占用:无需 KV‑cache,显存需求保持稳定,适配低算力部署环境。
- 统一建模:在理论上可以兼容离散与连续时间信号,拓展到音频、视频等多模态任务。
这些特性直接对应 Transformer 在大规模推理场景中的痛点,使得 SSM 成为硬件受限环境下的天然替代方案。
近期进展与竞争力
截至 2026 年 3 月,多个公开基准显示,最新的 SSM 变体在语言建模困惑度、少样本学习和推理速度上已经逼近甚至超越同等规模的 Transformer。研究社区报告称,
- 在 1M token 长度的基准测试中,SSM 推理时间比 Transformer 快约 3‑5 倍。
- 在保持相似参数规模的前提下,模型的推理显存占用下降超过 30%。
这些数据表明,SSM 正从“好奇心项目”转向能够在实际产品中直接替代 Transformer 的竞争者。
前景与挑战
尽管 SSM 已展示出显著的效率优势,但仍面临若干技术壁垒:
- 训练稳定性:大规模训练时的数值误差仍需更成熟的正则化手段。
- 通用性验证:在跨任务迁移和多模态融合方面的表现尚未完全匹配 Transformer 的成熟度。
- 生态支持:主流深度学习框架对 SSM 的原生加速尚在起步阶段,社区工具链仍需完善。
综合来看,状态空间模型正站在技术转折点上。若上述挑战得到有效解决,它有望在算力受限的场景中成为新一代序列建模标准,为大模型的可持续发展打开新路径。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。