Meta与斯坦福联合提出快速字节潜在变换器 大幅降低推理带宽
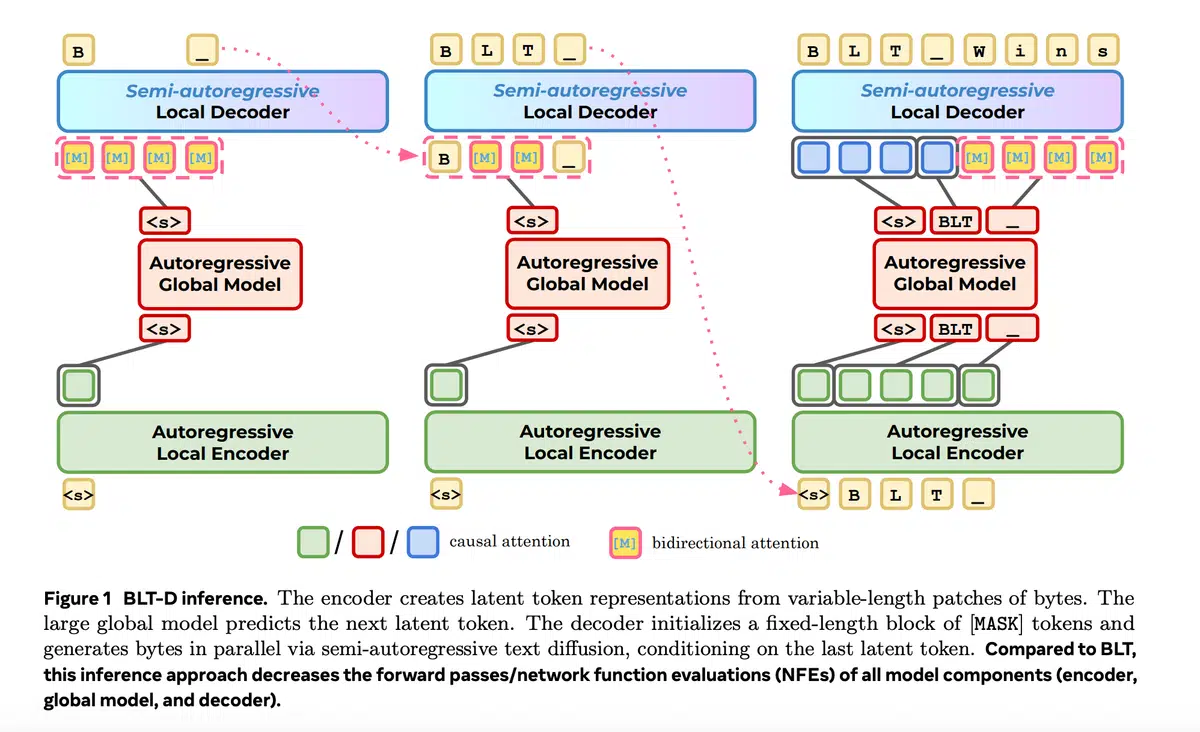
背景
传统大型语言模型大多基于子词分词(如 BPE),虽然计算高效,却在多语言、代码和数字等细粒度场景上表现脆弱。Meta 提出的 Byte Latent Transformer(BLT)直接在原始字节上建模,通过熵驱动的可变长度切片,将字节聚合为潜在 token,克服了分词的局限。但 BLT 在推理时仍需逐字节自回归解码,导致多次权重与 KV‑cache 读取,成为内存带宽的主要瓶颈。
方法概述
研究团队提出三种互补技术,统一目标是减少 Decoder 前向调用次数,从而降低带宽消耗。
-
BLT Diffusion(BLT‑D):在局部解码器中加入块级离散扩散训练。训练时向固定长度字节块随机掩码,模型需同时预测原始字节和被掩码的字节。推理时一次前向可解码多个字节,采用置信度阈值或熵上界两种采样策略。
-
BLT Self‑Speculation(BLT‑S):利用已有轻量局部解码器作为草稿模型,无需额外模型或结构改动。解码器在固定窗口(8/16 字节)内生成草稿,然后完整模型重新编码并校验,首次不匹配即回滚。该过程在贪婪解码下保证输出与标准自回归完全一致。
-
BLT Diffusion+Verification(BLT‑DV):将 BLT‑D 的扩散草稿与一次自回归校验相结合,单步扩散后通过因果遮罩验证,既保留扩散的高效性,又恢复质量。
实验结果与分析
所有模型均在 BLT‑1T(1 万亿字节)数据集上训练,3B 参数模型为例:
- BLT‑D‑4(块大小 4)在保持任务分数的同时,将估算带宽削减至 45% 以下。
- BLT‑D‑16 达到 87%‑92% 的带宽下降,但在 HumanEval、MBPP 等代码基准上出现显著的 pass@1 下降。
- BLT‑S(窗口 16)在不牺牲任务性能的前提下,实现约 77% 的带宽削减。
- BLT‑DV 综合两者优势,最高可达 81% 带宽降低,且质量基本恢复至原始 BLT 水平。
在五项基准(ARC‑Easy、ARC‑Challenge、PIQA、HellaSwag、MMLU)上,BLT‑D 系列的得分与原始 BLT 相差无几,证明离散扩散并未削弱模型的推理能力。进一步的多样性实验显示,提升解码器 NFEs 可提升词汇多样性,提供了可调的效率‑多样性平衡点。
影响与展望
该工作展示了在不引入额外模型或重新设计架构的前提下,利用扩散和投机解码即可显著降低字节级模型的内存带宽需求,为实际部署提供了可行路径。作者指出,真正的墙时加速仍依赖高度优化的推理实现,未来工作将聚焦于硬件‑软件协同和 KV‑cache 压缩技术。若成功落地,字节级模型有望在多语言、代码生成以及低资源设备上获得更广泛应用,进一步削弱对传统分词的依赖,实现更为细粒度的文本理解与生成。