阿里巴巴Qwen团队推出Qwen3.5‑LiveTranslate‑Flash,2.8秒实现60语种实时多模态翻译
•19 阅读•4分钟•应用
语音克隆Qwen多模态Alibaba实时翻译
•19 阅读•4分钟•应用
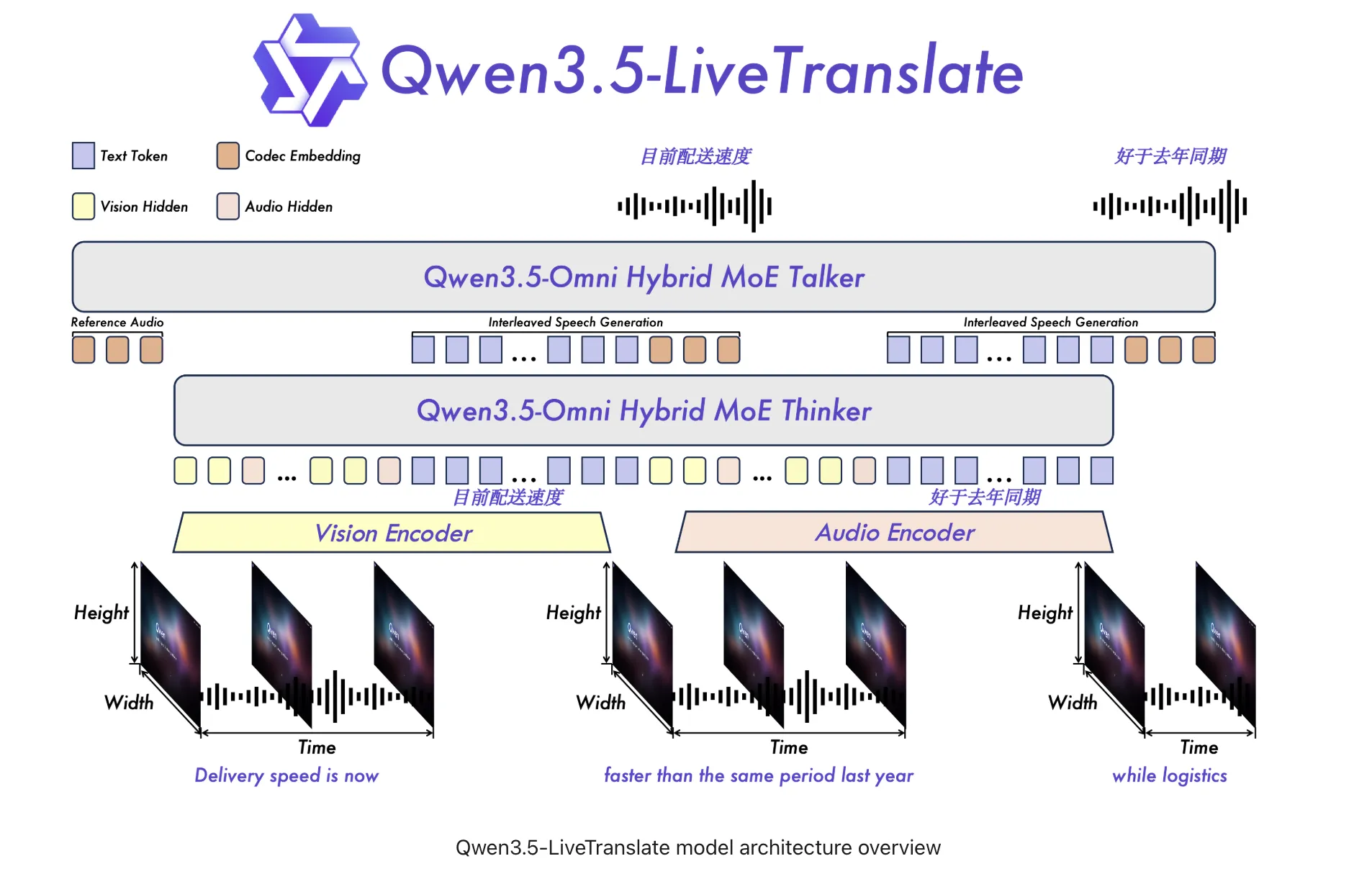
背景与意义
实时同声传译一直是跨语言沟通的技术瓶颈。传统系统往往在音频完整后才开始翻译,导致延迟数秒,破坏“实时”体验。阿里巴巴Qwen团队在此前的Qwen‑LiveTranslate‑Flash基础上,推出Qwen3.5‑LiveTranslate‑Flash,将时延压至2.8秒,并将语言覆盖从18种提升至60种,显著降低企业多语言产品的集成成本。
关键技术突破
- 语义单元预测:模型在接收音频流的同时,依据累计语义信息判断“阅读单元”,在句子未说完时即触发翻译输出,实现连续流式翻译。
- 视觉增强感知:同步摄取视频帧,解析唇形、手势以及屏幕文字。当音频噪声较大或发音模糊时,视觉信息可自动填补语义空缺,提高翻译准确度。
- 实时声纹克隆:仅凭单句语音即可捕获说话人声纹,翻译输出使用与原 speaker 相似的声音,避免传统合成音的机械感,提升听感自然度。
- 动态关键词注入:开发者可在会话启动时上传领域专属词表(如医学、法律、品牌名称),模型在翻译过程中优先使用这些术语,显著降低专业场景的误译风险。
多模态与实时语音克隆的实际价值
- 会议直播:在嘈杂的会议厅或线上研讨会中,视觉通道帮助系统在背景噪声下仍保持高翻译质量。
- 跨国客服:实时声纹克隆让客户感受到“同一位客服”在不同语言间切换,提升服务满意度。
- 多语言内容生产:企业可通过单一 API 实现音视频内容的多语言同步发布,降低多语言运营成本。
性能评估
在公开的多语言语音翻译基准 FLEURS 与 CoVoST2 上,Qwen3.5‑LiveTranslate‑Flash 的 BLEU/COMET 分数均超出市面主流商业模型(如 Google Cloud Speech、Microsoft Azure Translator),尤其在噪声环境下的鲁棒性提升最为显著。
使用指南概览
- 账户准备:在阿里云模型工作室开通账户并获取 DashScope API Key。
- 协议连接:模型采用 WebSocket 持久连接,支持一次会话内多轮音视频流式传输。
- 音视频输入:音频需为 16kHz、16‑bit PCM 单声道;视频帧可使用 JPEG 编码的 Base64 数据,帧率约 2fps 已足够。
- 关键词配置:在
session.update消息中填入keywords列表,即可实现领域词汇的即时定制。 - 输出:模型返回实时翻译文本,同时可选返回目标语言的语音流(仅限 29 种支持语音的语言)。
示例代码(Python)已在官方博客提供,涵盖从连接、配置到流媒体发送的完整流程,开发者可直接基于示例进行二次开发。
市场影响与展望
Qwen3.5‑LiveTranslate‑Flash 将实时多模态翻译的门槛进一步降低,预计将在跨国会议、线上教育、国际媒体以及企业客服等场景快速落地。随着阿里云生态的持续开放,更多第三方工具和平台将基于该模型构建定制化同声传译解决方案,推动全球企业的语言协同进入“秒级”时代。
本文基于阿里巴巴官方博客及 MarkTechPost 报道整理,旨在为业界提供客观、完整的技术概览。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。