Fastino Labs发布GLiGuard,300M参数安全模型实现16倍加速,精准度媲美上百倍大模型
•41 阅读•4分钟•开源
Fastino LabsGLiGuard安全防护编码器模型LLM Guardrails
•41 阅读•4分钟•开源
背景与意义
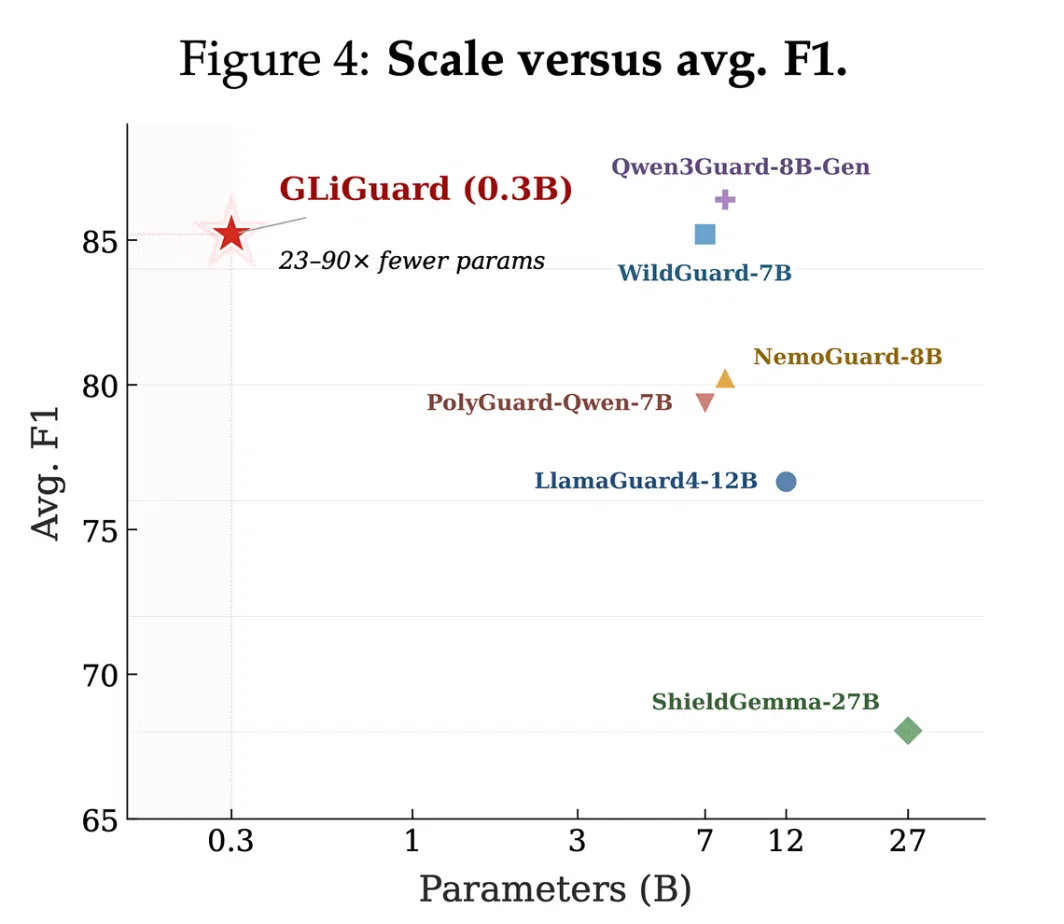
随着大语言模型(LLM)被广泛用于生产系统,安全防护成为成本最高的环节。传统的守护模型多基于解码器结构,需逐 token 生成判定,导致每轮对话都产生显著的延迟和算力开销。Fastino Labs针对这一痛点,推出了 GLiGuard——一款仅 300M 参数、基于编码器的多任务安全分类模型,旨在用更小的体积实现与数十倍更大的模型相当的准确率,同时大幅提升响应速度。
核心技术
- 编码器单通路:GLiGuard 将安全任务统一视为文本分类问题,输入文本与任务标签一起编码,一次前向传播即可为所有任务打分。
- 四项安全任务:
- 安全性判定(安全/不安全)——覆盖用户提示和模型回复。
- 越狱策略检测(11 种常见策略),如提示注入、角色扮演绕过等。
- 危害类别分类(14 类),包括暴力、色情、仇恨、PII、误信息、儿童安全、版权等。
- 拒绝检测(合规/拒绝),帮助衡量过度拒绝与伪合规。
- 高效推理:在单块 NVIDIA A100 上,批大小 4 时吞吐量达 133 条/秒,单次推理延迟仅 26 ms,较同类解码器模型(如 ShieldGemma‑27B)快 16 倍以上。
训练数据与微调
GLiGuard 使用了 87,000 条人工标注的 WildGuardTrain 数据,覆盖提示安全、回复安全和拒绝检测。危害类别和越狱策略的标注则借助 GPT‑4.1 生成合成样本,并在早期训练阶段加入 Pioneer 生成的细粒度边缘案例,以提升对相似危害的区分能力。模型基于 Fastino 自研的 GLiNER2‑base‑v1 检查点,采用 AdamW 优化器全参数微调 20 个 epoch。
基准评测
GLiGuard 在 9 项公开安全基准上取得了令人惊讶的成绩:
- Prompt Classification:平均 F1=87.7,仅比最佳模型 PolyGuard‑Qwen(89.4)低 1.7 分。
- Response Classification:平均 F1=82.7,排名第二,仅次于 Qwen3Guard‑8B(84.1)。
- 与 LlamaGuard‑4‑12B、ShieldGemma‑27B、NemoGuard‑8B 等上百倍参数模型相比,准确率持平或超出。
- 速度:在相同硬件上,GLiGuard 的吞吐量提升 16.2 倍,延迟降低 16.6 倍(26 ms vs 426 ms)。
部署与生态
GLiGuard 采用 Apache 2.0 许可证,模型权重已发布于 Hugging Face(fastino/gliguard-LLMGuardrails-300M),可直接在单卡 GPU 上运行,也支持 Fastino 的 Pioneer 托管推理服务。社区可以基于其编码器结构进一步微调,以适配特定行业的安全需求。
行业影响
- 成本下降:仅 300M 参数即可替代数十倍规模的守护模型,显著降低算力费用。
- 实时交互:毫秒级的判定延迟让安全检测不再成为多轮对话的瓶颈。
- 开源生态:在 Apache 2.0 下自由使用,促进了安全模型的标准化与协同改进。
“安全防护不应牺牲效率,GLiGuard 为生产级 LLM 应用提供了可行的技术路径。”——Fastino Labs 研发团队
随着生成式 AI 场景的快速落地,GLiGuard 的出现为企业在保障合规的同时保持高并发提供了新选项,也为后续的 编码器式安全模型 研究指明了方向。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。