Finbarr Timbers回顾2026前沿后训练配方,揭示多教师在策略蒸馏成主流
•0 阅读•4分钟•前沿
DeepSeek V4Finbarr TimbersMiMo FlashNemotron 3 UltraMOPD
•0 阅读•4分钟•前沿
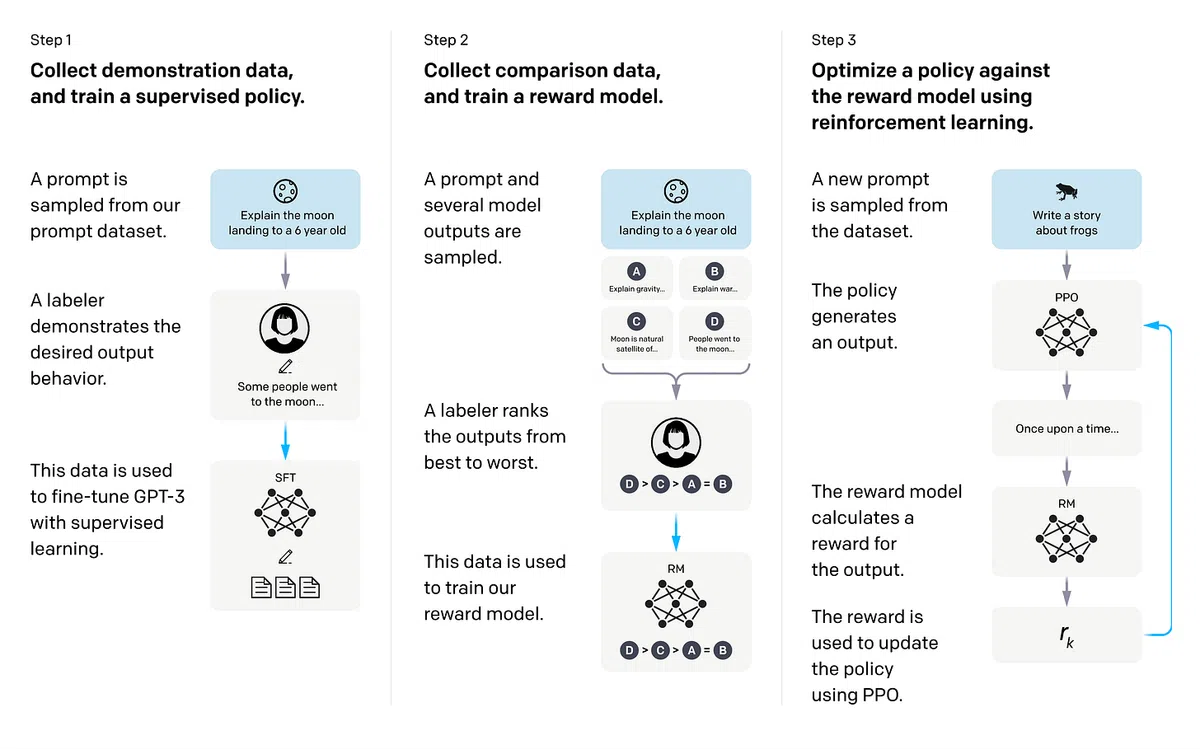
背景与历史回顾
Finbarr Timbers在播客中首先梳理了后训练(post‑training)配方的演进路径。自2022年InstructGPT提出的三阶段 SFT → Reward Model → RL 方案起,随后出现了 Llama 2/3、Tülu 3 等模型的 SFT → DPO → RL 变体,进一步细化了奖励模型的角色。2025 年 DeepSeek R1 将 RL 置于核心,形成 R1‑Zero → Reasoning RL → SFT → RL → Distill 的复杂链路。进入2026 年,MiMo Flash V2、DeepSeek V4、Nemotron 3 Ultra 等模型引入 多教师在策略蒸馏(MOPD),标志着配方向模块化、并行化转型。
关键技术演进
- InstructGPT (2022‑2023):单一流水线,SFT + 奖励模型 + PPO。
- Llama 3 / Tülu 3 (2024):加入 DPO,奖励模型可验证,RL 仍为闭环。
- DeepSeek R1 (2025):RL 成为主体,利用大规模 RLVR(可验证奖励)提升推理能力。
- MiMo Flash V2 (2026):首次系统化 MOPD,训练 N 个领域专家教师(数学、代码、推理、代理等),再通过学生模型的自采样轨迹在每一步最小化 reverse‑KL,实现在策略上的多教师蒸馏。
- Nemotron 3 Ultra (2026):两轮 MOPD,教师数量超过 10,结合专用的 Mamba‑Sparse Attention,进一步提升算力利用率。
多教师在策略蒸馏 (MOPD) 的核心要点
- 教师模型分工:每个教师专注单一领域,先完成 SFT 再进行领域‑RL。
- 学生模型自采样:学生在训练期间自行生成轨迹,按所属领域路由至对应教师。
- KL 蒸馏损失:在每个 token 上最小化学生分布与教师分布的逆 KL,确保学生逐步逼近教师行为。
- 多轮迭代:多数前沿模型采用两轮甚至三轮 MOPD,以逐步融合新教师并修正分布偏差。
“教师与学生训练管线不一致会导致分布错配,进而削弱蒸馏效果”,——Nemotron 3 Ultra 论文摘要。
产业影响与前景
- 算力与组织规模:MOPD 将原本需要一次性大规模 RL 的算力需求拆分为多次小规模教师训练,降低单轮 RL 的成本,同时对组织结构更友好——只需并行管理若干领域团队。
- 模型效率:通过专用教师的深度微调,学生模型在通用基准上可获得 1‑2% 的显著提升,且在特定任务上往往超过 5% 的增益。
- 竞争格局:OpenAI、Anthropic 等仍以整体 RLHF 为主,而 NVIDIA、DeepSeek、MiMo 等已普遍采用 MOPD,形成技术分化。
- 开源趋势:部分实验室(如中国的月之暗面)已开始公开教师模型和蒸馏脚本,推动社区复现和迭代。
小结
Finbarr Timbers 的回顾表明,后训练配方已从单一的三阶段流水线,演进为高度模块化的 多教师‑在策略蒸馏 体系。该体系不仅解决了大规模 RL 的算力瓶颈,也为组织内部的专业化分工提供了可行路径。随着算力成本进一步下降,MOPD 有望成为大模型研发的标准流程,推动生成式 AI 向更高效、更专业的方向发展。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。