百度发布Unlimited OCR实现长文档无缝解析 KV缓存保持平稳
•0 阅读•3分钟•开源
百度Mixture-of-ExpertsOmniDocBenchUnlimited OCRR-SWA
•0 阅读•3分钟•开源
背景
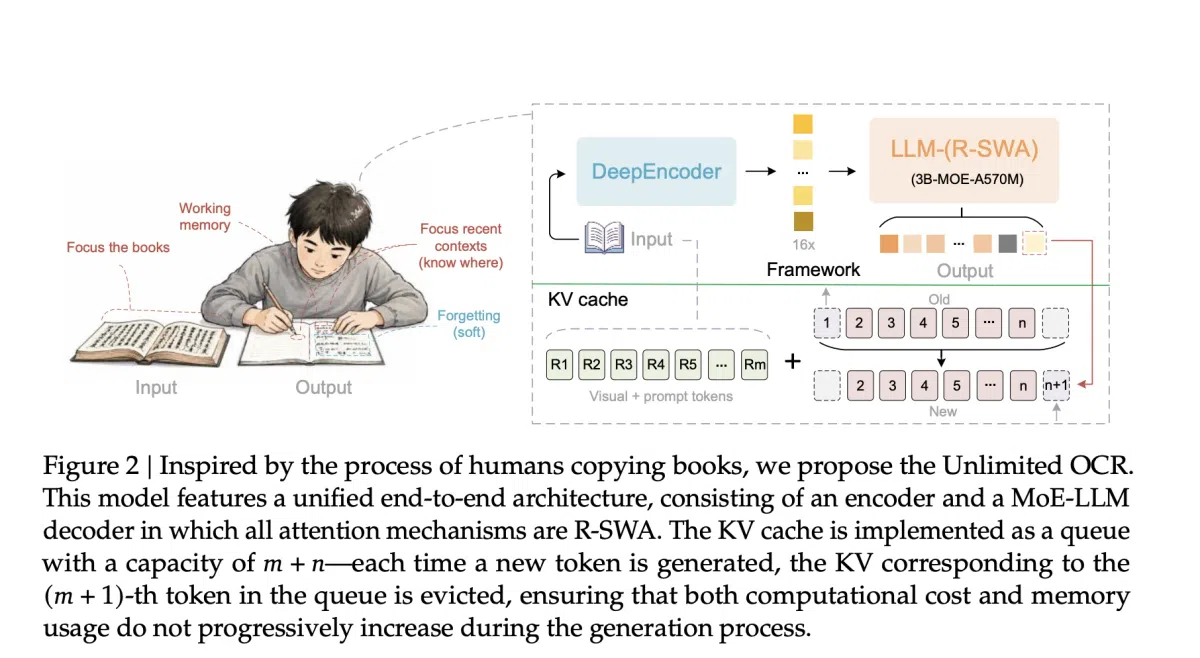
传统端到端OCR模型在输出长度增加时会导致KV缓存线性增长,内存占用和推理时延随之飙升,使得多页文档的批量解析几乎不可行。为了解决这一瓶颈,百度在DeepSeek OCR的基础上继续训练,推出了全新模型Unlimited OCR。
技术创新
- Reference Sliding Window Attention(R‑SWA):每个生成 token 仅关注全部参考视觉 token 与最近的n个输出 token(默认 n=128),旧 token 被自动逐出缓存,缓存大小固定为
Lm + n,实现了恒定的内存占用和时延。 - Mixture‑of‑Experts(MoE)架构:模型总参数量3B,但推理时仅激活约500M参数,保持高效算力需求。
- DeepEncoder 设计:采用 SAM‑ViT 与全局注意力的 CLIP‑ViT 双流编码器,对 1024×1024 PDF 页面进行 256 视觉 token 的压缩,实现 16 倍 token 压缩率。
- 两种分辨率模式:Base 模式固定 1024×1024 适用于多页批处理,Gundam 模式支持单页动态分辨率,提升细粒度识别效果。
性能评测
| 模型 | OmniDocBench v1.5 | OmniDocBench v1.6 | TPS(Base 模式) |
|---|---|---|---|
| DeepSeek OCR | 87.01 | 90.45 | 4,951 |
| Unlimited OCR | 93.23 (+6.22) | 93.92 | 5,580 (+12.7%) |
在文本、公式、表格以及阅读顺序四大子任务上均实现全线提升,编辑距离保持在 0.11 以下,长文档(40+页)解析误差低于 0.11,展示了模型的稳健性。
开源与应用
- MIT 许可证:模型权重、代码及推理脚本全部开源,社区可直接
from_pretrained("baidu/Unlimited-OCR")使用。 - 推理接口:提供原生 Transformers 接口以及基于 SGLang 的 OpenAI‑compatible API,支持高并发批量解析。
- 适用场景:整本书籍一次性转录、企业文档管线化提取、海量 PDF 批处理等,对 KV 缓存敏感的长序列任务尤为适合。
局限与展望
虽然 R‑SWA 将缓存保持在常数,但预填阶段仍受 32K 上下文限制;多页运行仅支持 Base 模式,极小文本可能出现漏检。团队计划将 R‑SWA 拓展至语音识别(ASR)和机器翻译等跨模态任务,进一步验证其通用性。
结语
Unlimited OCR 的发布标志着中文 OCR 技术在长文档解析效率上的一次质的飞跃。凭借常数 KV 缓存、低激活参数量以及开源生态,预计将在学术研究与产业落地之间搭建更紧密的桥梁。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。